
Exploring the Jackrabbit Java Content Repository
Rapid Rabbit

© sad, Fotolia
Speed up your web development with Jackrabbit, an open source implementation of the Java Content Repository standard.
Databases and conventional data structures are not always a perfect solution for web development. A web application, such as a staff portal on an intranet, for example, has specific requirements for how and when users can access the data. Users have different needs with respect to the data as well. For example, some are interested in targeted content searches, whereas others want to be notified when significant events occur, and all users need access privileges to modify content.
To put it in more general terms: Simply providing content is not enough. Today's users – and today's web developers – expect that various services will accompany the content. For example, web applications often rely on access controls, search functions, and versioning, and, although the developer could build these functions into the application from scratch, the economies of the programming profession cry out for a more efficient approach.
The idea behind the Content Repository API for Java Technology (JCR) is to abstract data-related services from the underlying application and use a standard API to access these service. A content repository avoids the need to continually re-implement data services with each application. Instead, the application simply calls a function through the repository API.
A content repository combines some of the advantages of a filesystem and a database. As a filesystem, it supports hierarchical storage of unstructured files and permissions for access control. As a database, it supports storage of structured data, queries, transactions, and integrity checks. Content repositories also support features such as versioning and change management (Figure 1).
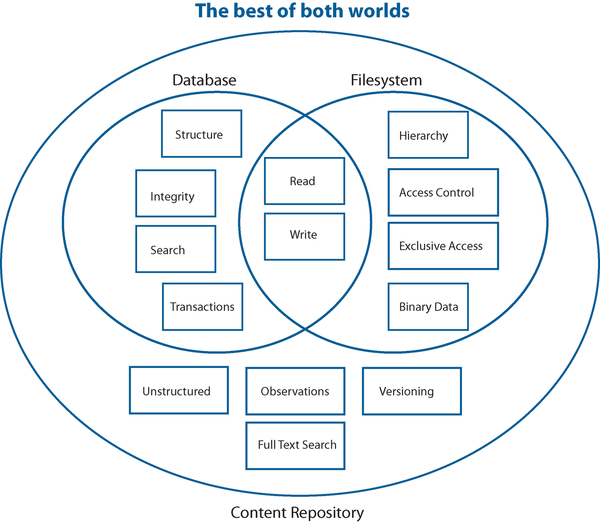 Figure 1: A content repository combines the advantages of databases and filesystems.
Figure 1: A content repository combines the advantages of databases and filesystems.
The Content Repository
The full specification for the Content Repository standard is an excellent starting point if you want to get to know the Java Content Repository API [1]. The idea is that the definition of a repository is independent of the underlying data sources, protocols, and architecture. The API is split into two levels. Level 1 provides basic functionality for read access, and level 2 addresses issues related to modifying stored data.
The JCR reference implementation was created by Day Software and then handed over to the Apache Software Foundation. This implementation has since become a successful open source project that goes by the name of Apache Jackrabbit [2]. An active community has grown around the project and continues to push its development. The Jackrabbit repository is a full-fledged implementation of the standard, with a full set of level 1 and level 2 functions. Jackrabbit also adds several extra features, such as the ability to set up a repository cluster.
A web application included with Jackrabbit supports the first few steps of defining a content repository. This web app provides an interface that gives users the ability to set up new repositories.
Apache Jackrabbit supports access to the repository via WebDAV, which makes it easy to mount the repository, copy any kind of files to it, create directories, and manage the repository contents.
Figure 2 shows an overview of the repository model: It has a simple, hierarchical structure as a tree with n levels. The central instance is the repository, which can contain one or multiple workspaces. In turn, each workspace contains a tree of items, wherein each item is either a node or a property. A node can have child nodes, and 0 to n properties that store the data (see the "Types" box). A property is typed and contains a data type (string, number, binary string, and so on).
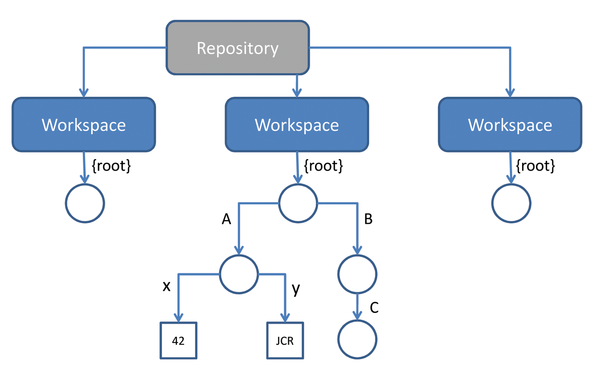 Figure 2: The repository model: The workspace is filled with nodes A, B, and C. Node A has the properties x and y.
Figure 2: The repository model: The workspace is filled with nodes A, B, and C. Node A has the properties x and y.
Nodes allow hierarchical data storage of, say, digital photos below a photos node. Other nodes in the repository represent photo albums, which can also contain sub-albums. For instance, all photos taken in the year 2008 in Amsterdam might reside below /photos/2008/Amsterdam. Each item, whether a node or a property, can be uniquely accessed via a path starting at the repository root. Below the Amsterdam node are photos, and each photo has its own node. But a content repository is more than an ordinary collection of files and directories. The properties belonging to the individual nodes can include parameters useful to a web application, such as the binary stream for the image, as well as parameters such as the photo date and location. It is up to the developer to structure the data in the repository in the best way for the application. The Jackrabbit documentation and the wiki [3] offer tips and tricks for content modeling.
Types
Each node has exactly one primary type. This type defines the node structure, for example, specifying which properties or children the node can possess. Besides the primary type, a node can have any number of mixins. A mixin is also a type definition that can add properties to any node. Each application can define its own types. The combination of multiple inheritance and mixins supports extremely flexible and precise type definition. The standard defines a number of types, such as nt:unstructured, with which arbitrary trees made of nodes and properties are permitted.
It is generally a good idea to use existing types and then add your own requirements. For a photo album, this would mean using an existing type such as nt:folder, which describes a directory, with your own mixin that contains additional information for the album. At the same time, images could use nt:file and a mixin for special photo data. The use of standard types also offers the advantage of helping third-party applications handle the data more easily.
The Java API
Interacting with the repository requires a couple of initial steps: Application programmers first have to set up a connection to the repository and then create a session for an individual user. All further actions use the session. The first step for accessing the repository is not defined by the standard. Depending on how the infrastructure is implemented, Apache Jackrabbit offers various approaches. One approach uses the Java Naming and Directory Interface (JNDI). The code in Listing 1 creates a session for a fictional user.
Listing 1
Accessing the Repository
Developers can use the session to query and modify nodes. In case of changes, the repository does not save them itself; instead, a message is sent to the session, which means that multiple changes can be saved at the same time. On top of this are explicit transactions. The code in Listing 2 queries a node (i.e., /photos/2008) in a repository. Below this node, it creates a new Amsterdam node, assigns properties, and saves the changes.
Listing 2
Reading and Writing in the Repository
The API supports a search function via SQL or XPath to support complex queries. To track changes to the repository, reference the EventListeners registered with the session. Users can specify which parts of the repository to monitor during the registration process and restrict notification to specific types and changes. With the last feature, it is easy to launch a specific workflow for a specific type of content in the repository. Different applications or their components can thus react to each other flexibly while remaining loosely connected. For example, many application could store images in the same photo album.
The new Apache Sling framework [4] is based on a content repository for REST-based applications. Each browser query is matched with content in the repository, and a script for displaying the content is selected in a second step.
Development: JSR 283
Version 2 of the standard is currently under construction as JSR 283. The new standard, which is planned for a 2008 release date, will include a number of extensions. The major focus is on improving repository management and administrative functionality. For example, the current standard does not concern itself with access control and the type management of nodes. JSR 283 will close these gaps [5].
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Linux Servers Targeted by Akira Ransomware
A group of bad actors who have already extorted $42 million have their sights set on the Linux platform.
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs