
Parallel Programming with OpenMP
High Speed

© timbec, photcase.com
OpenMP brings the power of multiprocessing to your C, C++, and Fortran programs.
If you bought a new computer recently, or if you are wading through advertising material because you plan to buy a computer soon, you will be familiar with terms such as "Dual Core" and "Quad Core." A whole new crop of consumer computers includes two- or even four-core CPUs, taking the humble PC into what used to be the domain of high-end servers and workstations. But just because you have a multi-processor system doesn't mean all the processors are working hard.
In reality, often only one processor is busy. Figure 1 shows the top program output for Xaos, a fractal calculation program. The program seems to be using 100 percent of the CPU. But appearances can be deceptive: The computer's actual load is just 60 percent.
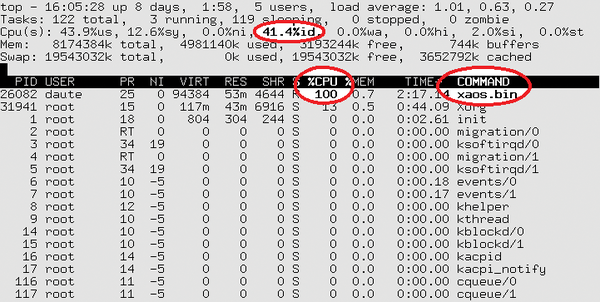 Figure 1: By default, top shows the total load for all CPUs …
Figure 1: By default, top shows the total load for all CPUs …
Pressing the 1 button lists the CPUs separately. In this mode (Figure 2), you can easily see the load on the individual cores: One CPU is working hard (90 percent load), while the other is twiddling its thumbs (0.3 percent load).
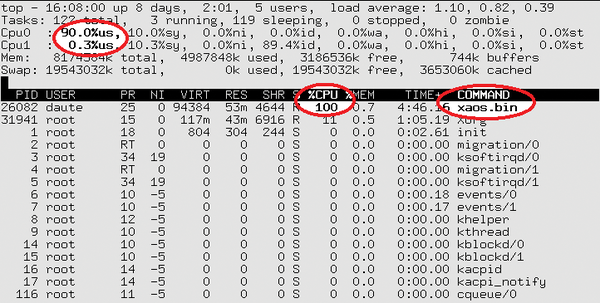 Figure 2: … but on request it will give you the load for the individual processor cores.
Figure 2: … but on request it will give you the load for the individual processor cores.
Linux introduced support for multiple processor systems many moons ago, and the distributors now install the multiple CPU--capable SMP kernel by default. Linux, therefore, has what it takes to leverage the power of multiple cores. But what about the software?
A program running on the system must be aware of the multiple processor architecture in order to realize the performance benefits. OpenMP is an API specification for "… multi-threaded, shared memory parallelization" [1]. The OpenMP specification defines a set of compiler directives, run-time library routines, and environment variables for supporting multi-processor environments.
C/C++, and Fortran programmers can use OpenMP to create new multi-processor-ready programs and to convert existing programs to run efficiently in multi-processor environments.
Multi-Tracking
A computer will work its way sequentially – that is, one instruction after another – through programs written in C/C++ or some other programming language. Of course, this technique will only keep one processor core busy. Parallelization lets you make more efficient use of a multi-processor system.
The OpenMP programming interface, which has been under constant development by various hardware and compiler manufacturers since 1997, provides a very simple and portable option for parallelizing programs written in C/C++ and Fortran.
OpenMP can boost the performance of a program significantly, but only if the CPU really has to work hard – and if the task lends itself to parallelization. Such is often the case when working with computationally intensive programs.
One, Two, Many
The OpenMP API supplies programmers with a simple option for effectively parallelizing their existing serial programs through the specification of a couple of additional compiler directives, which would look something like the following code snippet:
#pragma omp name_of_directive [clauses]
Compilers that don't support OpenMP, such as older versions of GCC before version 4.2, will just ignore the compiler directives, meaning that the source code can still be complied as serial code:
$ gcc -Wall test.c test.c: In function 'main': test.c:12: warning: ignoring #pragma omp parallel
OpenMP-specific code can also be compiled conditionally, with the #ifdef directive: OpenMP defines the _OPENMP macro for this purpose.
An OpenMP program launches normally as a serial program with one thread. One instruction arrives after another. The first OpenMP statement I will introduce creates multiple threads:
... one Thread
#pragma omp parallel
{ ... many threads }
... one threadFigure 3 shows how the program is distributed over multiple threads and then reunited to a single thread.
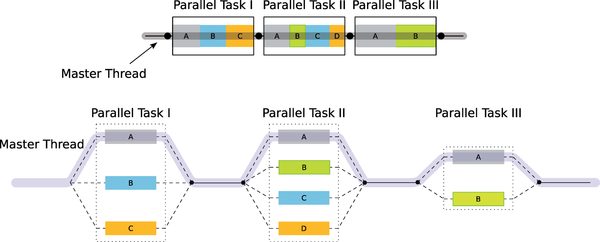 Figure 3: The OpenMP Fork-Join model.
Figure 3: The OpenMP Fork-Join model.
Divide and Conquer
Now you have created multiple threads, but at the moment, they are all doing the same thing. The idea is that the threads should each handle their share of the workload at the same time. The programming language C has two approaches to this problem. Fortran, a programming language that is popular in scientific research, has a third approach: "parallel work sharing."
The first variant, parallel sections, runs program sections (blocks of program code that are not interdependent) that support parallel execution, parallel to one another.
So that this can happen, #pragma omp parallel defines multiple threads. This means that you can run multiple, independent program blocks in individual threads with no restrictions on the number of parallel sections (Listing 1, Variant 1: Parallel Sections). Also, you can combine the two compiler directives, parallel and sections, to form a single directive, as in #pragma omp parallel sections.
The second variant, parallel for() loops, parallelizes for loops, which is especially useful in the case of computationally intensive mathematical programs (Listing 1, Variant 2: Parallel Loops).
Listing 1
Parallel Sections and Loops
... /* one thread */
#pragma omp parallel /* many threads */
{
#pragma omp sections
#pragma omp section
... /* Program section A running parallel to B and C */
#pragma omp section
... /* Program section B running parallel to A and C */
#pragma omp section
... /* Program section C running parallel to A and B */
}
... /* one thread */ ... /* a thread */
#pragma omp parallel [clauses ...]
#pragma omp for [clauses ...]
for (i=0;i<N;i++) {
a[i]= i*i; /* parallelized */
}
... /* one thread */
Figure 4 shows how this works. Again you can combine #pragma omp parallel and #pragma omp for to #pragma omp parallel for.
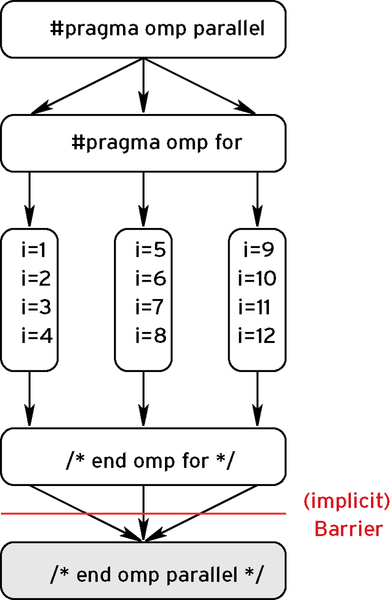 Figure 4: A Parallel for Loop.
Figure 4: A Parallel for Loop.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs
-
Juno Computers Launches Another Linux Laptop
If you're looking for a powerhouse laptop that runs Ubuntu, the Juno Computers Neptune 17 v6 should be on your radar.
-
ZorinOS 17.1 Released, Includes Improved Windows App Support
If you need or desire to run Windows applications on Linux, there's one distribution intent on making that easier for you and its new release further improves that feature.