
Intel's powerful new Xeon Phi co-processor
Power Plant

© Lead Image © Tomas Hajek, 123RF.com
The Xeon Phi accelerator card from Intel takes an unusual approach: Instead of GPUs, the Xeon Phi features a cluster of CPUs for easier programming.
In the high-performance computing field, an increasing number of users have turned to GPU computing, wherein a host computer copies data to the graphics card, which then returns a result.
This procedure is especially helpful for applications that repeatedly run the same operation against a large volume of data. A GPU can play to its strength, performing a large number of computations, each of which processes one data element. GPUs can process some types of calculations (such as mining bitcoins) orders of magnitude more efficiently than CPUs.
This performance advantage comes at a price. The programming model, and thus the programming procedure, differs fundamentally from that of CPUs. As a consequence, existing programs cannot run directly on GPUs. Although the OpenCL parallel programming framework tries to hide and abstract as many of these differences as possible, developers still need to be aware of the differences between coding for CPUs and GPUs.
This problem is one of the reasons Intel decided to look for an intermediate path, introducing the Xeon Phi accelerator at the beginning of this year. The Xeon Phi, which is based on x86 technology, has received more attention in recent months, mainly because it is inside the world's fastest supercomputer – the Tianhe-2 [1]; in fact, the 48,000 Xeon Phi cards built in to the Tianhe-2 help it deliver nearly twice the raw performance of the second-place contender: the GPU-based Cray Titan [2]. This article describes the Xeon Phi card and shows how it is different.
Single- to Multiple- to Many-Core
In 2005, Intel reached a dead end with its NetBurst microarchitecture and buried the decades-old dogma that a higher clock speed is the best way to more power. Since then, the company has increased the capacity of its chipsets despite only modest changes to clock speeds by improving the microarchitecture and relying on multicore technology.
To take full advantage of additional processing power, developers need to adapt their programs for multiple-core systems. Intel launched the Tera-scale program to develop programming methods for future multicore and many-core architectures. As a first result of the Tera-scale research program, Intel introduced new hardware in 2007: the Teraflops Research Chip, also known as Polaris. Polaris included 80 simple cores and achieved a performance of 19.4GFLOPS per watt with a total capacity of 400GFLOPS [3]. Just for comparison's sake: The then state-of-the-art Core 2 Quad processor managed only 0.9GFLOPS per watt with a total capacity of 85GFLOPS.
Unfortunately, the Polaris was extremely difficult to program and was never available as a commercial product – only five people ever wrote software for the chip. Intel's next step was to develop the Single-Chip Cloud Computer (SCC, code-named: Rock Creek). The processor included 48 cores (24 units each with two cores), which were largely identical to the cores of the Pentium-1 (P54C) processors and communicated with each other via a high-speed network connection and four DDR-3 memory channels. Intel manufactured a few hundred SCCs and distributed them to their own labs, as well as to research institutions worldwide.
The SCC was capable of acting as a cluster on a chip, booting a separate Linux instance on each of the 48 cores. A single OS instance on all 48-cores is not possible with established operating systems because the SCC does not ensure cache coherency on the hardware side, unlike current commercial processors. In other words, changes to the data in one core's cache were not automatically propagated to caches of the other cores. Thus, efficient use necessitated different programming concepts and far-reaching changes to the operating system – or even a custom operating system.
Larrabee's Heritage
Starting in 2007, Intel tried to develop its own powerful GPU, which they code-named Larrabee. Unlike many GPUs, Larrabee would not consist of many special-purpose computing units but of numerous modified Pentium processors (P54C) that ran x86 code. The first-generation Larrabee was never launched on the market, probably because its was not powerful enough to compete with NVidia and AMD/ATI.
However, armed with the additional experience gained from the Tera-scale program, Intel decided to push on with the Larrabee project in the form of an accelerator card for HPC that would compete with NVidia's Tesla GPUs.
Initial prototypes went to research institutions to test the card's usability. The result is an accelerator card, code-named Knights Corner, which has been available commercially as the Xeon Phi since early 2013.
Architecture
The Xeon Phi is available as a PCI Express card in configurations that differ with respect to the number of available cores (57, 60, or 61), memory size (6, 8, or 16 GB), clock speed (1053, 1100, or 1238 MHz), and cooling concept (active or passive) [4].
The basic architecture is the same for all cards: Like the Larrabee, the Xeon Phi's CPU cores are based on first-generation Pentium (P54C) technology. Additionally, the architecture supports 64-bit and floating-point instructions (x87) and a vector unit with 32 512-bit registers, with support for processing 16 single-precision floating-point numbers or 32-bit integers in parallel. Furthermore, each core is multithreaded four times so that a 7100 series Xeon Phi with 61 cores can run up to 244 threads at the same time.
The cores each have a 64KB L1 cache and a 512KB L2 cache and are interconnected by a ring bus. Unlike most multiple-core processors, the Xeon Phi provides no shared cache between the cores; however, in contrast to SCC, Larrabee supports hardware-based cache coherency. Up to eight GDDR-5 memory controllers use two channels to connect the memory to the ring bus (Figure 1), to which the PCIe interface is also connected.
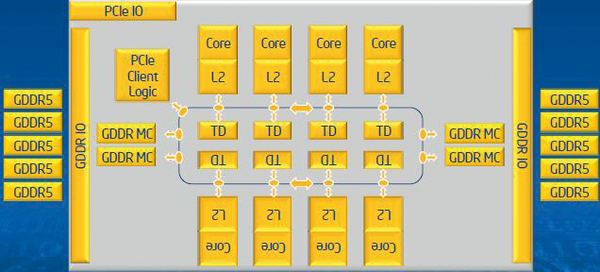 Figure 1: A ring bus interconnects the cores, providing access to PCIe through a client interface.
Figure 1: A ring bus interconnects the cores, providing access to PCIe through a client interface.
Besides the processor and memory, the Xeon Phi accelerator card also has sensors for monitoring temperature and power consumption. A system management controller makes this accessible to both the Xeon Phi processor and the host system. The controller can manage the processor, for example, to force a reboot of the card. Because the card does not have any input and output options, all data must flow through the PCIe interface and thus via the PCIe and system management buses. Physically, the card is about the same size (and uses the same sort of heat sinks) as a high-performance graphics card, but without the display outputs.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs
-
Juno Computers Launches Another Linux Laptop
If you're looking for a powerhouse laptop that runs Ubuntu, the Juno Computers Neptune 17 v6 should be on your radar.