
HDF5 for efficient I/O
Single Thread Process I/O
Among the previously mentioned ways that applications can perform I/O, Listing 6 shows how MPI tasks can each write a specific set of data to the same file. The example is fairly simple and illustrates the basics parallel I/O work with HDF5. The example is written in Fortran for two reasons: (1) It's easy to read, and (2) it's the scientific language of scientists.
Listing 6
Basic Parallel I/O with HDF5
For each MPI process to write an individual dataset to the same HDF5 file, the rank 0 MPI process initializes the HDF5 file and the dataspace with the appropriate properties and then closes the file. Next, each MPI process reopens the file and writes its data to and closes the HDF5 file. For the sake of brevity, the error codes returned from functions are not checked.
The following tasks are performed by the rank 0 process, which defines the HDF5 file and its attributes: Line 53 initializes the HDF5 file and properties, line 56 creates the HDF5 file, line 59 creates the dataspace, line 62 creates the data properties, line 65 is the call required when each process writes to a single file, lines 67-73 loop over all processes and create the dataset name and dataset for each process, line 76 closes the dataspace, line 79 closes the properties list, and line 82 closes the HDF5 file.
The following tasks are then performed by all of the processes: Line 89 creates a new properties list, line 90 sets the MPI-IO property, line 93 opens the file, line 96 closes the properties, line 103 opens the dataset, line 107 sets the MPI-IO property, lines 110-111 create a pointer to and write data to the dataset (a specific dataset for each process), and lines 114-125 close everything and finish up.
A quick run of the example with two processes creates the file test1.hdf5. Listing 7 shows the content of this file using the HDF5 h5dump tool. Both datasets are in the file, so each MPI process wrote its respective dataset.
Listing 7
Content of HDF5 File
Parallel I/O and HDF5
The previous discussion demonstrates a good way to get started with parallel I/O and HDF5, but it has some limitations. For example, each MPI process writes its portion of an array to a different dataset in the HDF5 file, so if you want to restart the application from the beginning, you would have to use the same number of MPI processes as used originally. A better solution would be for each MPI process to read and write its data to the same dataset, which allows the number of MPI processes to change without worrying about how the data is written in the HDF5 file.
The best way to achieve this is to use hyperslabs, or portions of datasets. It can be a contiguous section of a dataset, such as a block, a regular pattern of individual data values, or a block within a dataset. The 2x2 blocks in Table 1 are separated by a column and a row. Each 2x2 block or each row or column of a 2x2 block can be a hyperslab, depending on the design.
Table 1
Hyperslab Pattern
| | |
| |
| |
| |
| |
| |
| |
| | |
X |
X |
| |
X |
X |
| |
| | |
X |
X |
| |
X |
X |
| |
| | |
| |
| |
| |
| |
| |
| |
| | |
X |
X |
| |
X |
X |
| |
| | |
X |
X |
| |
X |
X |
| |
| | |
| |
| |
| |
| |
| |
| |
To describe a hyperslab completely, you need four parameters:
start– a starting locationstride– the number of elements that separate each element or block to be selectedcount– the number of elements or blocks to select along each dimensionblock– the size of the block selected from the dataspace
Each of the parameters is an array with a rank that is the same as the dataspace.
The HDF group has created several parallel examples. The simplest, ph5example [19], illustrates how to get started. In the code, the HDF5 calls are accomplished with MPI processes (all with the same data). The program in Listing 6, in which each MPI process wrote its own dataset, started with this example.
A number of HDF5 examples use hyperslab concepts for parallel I/O. Each MPI process writes a part of the data to the common dataset. The main page for these tutorials [20] has four hyperslab examples: writing datasets by contiguous hyperslab, by regularly spaced data, by pattern, and by chunk. Here, I go through the last example, which writes data to a common dataset by chunks.
In the Fortran example [21] (see an excerpt of the code in Listing 8), the number of processes is fixed at four to illustrate how each MPI process writes to a common dataset (Figure 3). The dataset is 4x8 (rows by columns), and each chunk is 2x4 (rows by columns).
Listing 8
Write by Chunk (Excerpt )
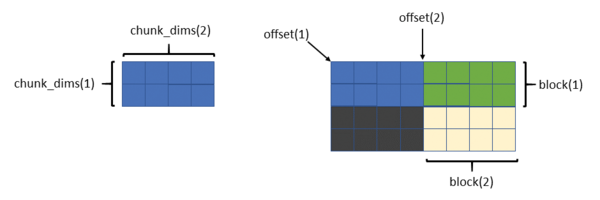 Figure 3: Data layout for contiguous "chunk" approach.
Figure 3: Data layout for contiguous "chunk" approach.
Recall that four parameters describe a hyperslab: start, stride, count, and block. The start parameter is also referred to as offset in the example (and other) code.
The dimensions of each chunk are given by the array chunk_dims. The first element is the width of the chunk (number of columns), and the second element is the height of the chunk (number of rows). For all MPI processes, block(1) = chunk_dims(1) and block(2) = chunk_dims(2).
Because the data from each process is a chunk, the stride array for each chunk is 1 (i.e., stride(1) = 1, stride(2) = 1, or a contiguous chunk). Some of the other examples have arrays for which stride is not 1. The array count for each chunk is also 1; that is, each MPI process is only writing a single chunk (count(1) = 1, and count(2) = 1).
What differs is the offset or start of each chunk. For clarity, the rank = 0 process writes the chunk in the bottom left portion of the dataset, so both elements of its offset arrays are 0. The rank = 1 process writes the bottom right chunk of the dataset. The offset array is offset(1) = chunk_dims(1) and offset(2) = 0.
MPI process 2 writes the top left-hand chunk. Its offset array is offset(1) = 0 and offset(2) = chunk_dims(2). Finally, MPI process 3 writes the top right-hand chunk. Its offset array is offset(1) = chunk_dims(1) and offset(2) = chunk_dims(2).
For each chunk, the data is an array of integers that correspond to rank (MPI process+1). The data in the rank 0 process has values of 1, the data in the rank 1 process has values of 2, and so on.
The process for writing hyperslab data to a single dataset is a little different from the first example, but for the most part, it is the same. When creating the dataspace, you have to call some extra functions to configure the hyperslabs.
To write the hyperslab to the dataset, each MPI process calls h5sselect_hyperslab_f to select the appropriate hyperslab using the four parameters mentioned before. All MPI processes then do a collective write, which puts the information into the header of the dataset. The second call writes the dataset to the location defined by the hyperslab for that process.
The code produces sds_chnk.h5, which contains the data shown in Listing 9.
Listing 9
Hyperslab Data
Because h5dump is written in C, the data writes to stdout in row-major [22] format (the opposite of column-major Fortran). With some transposing, you can see that the dataset is as expected.
It takes some work to write hyperslabs to the same dataset using MPI-IO. Read through the other examples in the parallel topics tutorial [20], particularly the writing to a dataset by pattern option, to understand how hyperslabs and MPI-IO can be used to reduce the I/O time of your application.
Summary
HDF5 has many features that make it probably the most used standard file format in HPC today. It's flexible, multiplatform, has a large number of language interfaces, and is easy to use.
In an effort to improve I/O performance and data organization, HDF5 uses a hierarchical approach to storing data.
HDF5 also allows you to associate metadata (attributes) with virtually any object in the data file. Taking advantage of attributes is the key to usable data files down the road. Attributes make HDF5 files self-describing. As with a database, you can access data randomly within a file.
Parallel HDF5 is included in the source code, allowing several processes, either on the same node or on different nodes, to write to the same file at the same time. This capability can reduce the time an application spends on I/O, because each process performs only a portion of the I/O.
HDF5 has a large number of wonderful features in addition to parallel performance, so it is definitely worth taking the time to experiment and to understand what it can do to improve application scalability and performance.
Infos
- Parallel I/O: http://www.admin-magazine.com/HPC/Articles/Improved-Performance-with-Parallel-I-O
- HDF: https://en.wikipedia.org/wiki/Hierarchical_Data_Format
- HDF5 tutorial: http://neondataskills.org/HDF5/Exploring-Data-HDFView
- HDFView: https://support.hdfgroup.org/products/java/hdfview/
- Perl support: http://search.cpan.org/~chm/PDL-IO-HDF5-0.6501/hdf5.pd
- Lua support: https://colberg.org/lua-hdf5/
- Node.js support: https://github.com/HDF-NI/hdf5.node
- Erlang support: https://github.com/RomanShestakov/erlhdf5
- Haskell support: https://hackage.haskell.org/package/bindings-hdf5
- Parallel HDF5: https://support.hdfgroup.org/HDF5/PHDF5/
- Predefined datatypes: https://support.hdfgroup.org/HDF5/doc/UG/HDF5_Users_Guide-Responsive%20HTML5/index.html#t=HDF5_Users_Guide%2FDatatypes%2FHDF5_Datatypes.htm%23TOC_6_2_2_Predefinedbc-4&rhtocid=6.1.0_2
- h5py Python library: http://www.h5py.org/
- Anaconda Python: https://www.continuum.io/downloads
- h5py Quick Start guide: http://docs.h5py.org/en/latest/quick.html
- NumPy: http://www.numpy.org/
- HDF5 Python docs: http://docs.h5py.org/en/latest/
- Fortran 90 examples in HDF5: https://support.hdfgroup.org/ftp/HDF5/examples/src-html/f90.html
- MPI-IO: http://beige.ucs.indiana.edu/I590/node86.html
- ph5example: https://support.hdfgroup.org/ftp/HDF5/current/src/unpacked/fortran/examples/ph5example.f90
- HDF5 parallel topics tutorial: https://support.hdfgroup.org/HDF5/Tutor/parallel.html
- Writing to a dataset by chunk: https://support.hdfgroup.org/ftp/HDF5/examples/parallel/hyperslab_by_chunk.f90
- Row-major order: https://en.wikipedia.org/wiki/Row-_and_column-major_order
« Previous 1 2 3 4
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs
-
Juno Computers Launches Another Linux Laptop
If you're looking for a powerhouse laptop that runs Ubuntu, the Juno Computers Neptune 17 v6 should be on your radar.