
Filesystems Benchmarked
Linux Filesystem Performance Tests
ByChoosing the right filesystem for a particular job can be a difficult task. We tested seven candidates and found some interesting results to make an administrator’s choice easier.
Admins building a new server or setting up a new storage device have to make important decisions on the basis of predicted usage. Does the server need to write millions of files quickly to keep the backup window manageable, or does it need to deliver multiple-gigabyte virtualization images within seconds?
The choice of filesystem can make a huge difference in such cases, so Linux Magazine put seven filesystems through numerous tests. The results of the benchmarks in this article could help readers choose the most appropriate filesystem for the task at hand.
The tests were performed on a Transtec Calleo appliance (see the “Test Hardware” box) with eight fast disks in a RAID level 0 array with a stripe size of 64KB. The RAID is divided into an SSD array and an HDD array with identical partitions on both arrays, thus also taking partition alignment, which is relevant for the hard disk’s performance, into account. The partition, therefore, starts at LBA address 2048.

Operating and Filesystems
The operating system used in the test was SUSE 12.1 with the latest updates and kernel 3.1.10. For the comparative tests with kernel 3.3.6 (from 12-5-2012 ), my choice fell on the largely identical rolling release, also based on SUSE 12.1, named openSUSE Tumbleweed.
The seven most widely used filesystems under Linux were the focus:
- ext2: The oldest ext filesystem, without journaling, and correspondingly with little protection against data loss if worst comes to worst.
- ext3: The long-term standard in many distributions.
- ext4: The latest ext standard since kernel 2.6.28.
- Btrfs: The newcomer, with properties similar to ZFS.
- XFS: A journaling filesystem developed by SGI.
- ReiserFS: The filesystem originally initiated by Hans Reiser.
- ZFS: A filesystem from the Sun universe that is considered by many experts to be the most advanced.
Note that ZFS, however, is not a competitor here, because it only recently became natively available on Linux – thanks to the “ZFS on Linux” project. Developer Paolo Pantò recently added it to the software index of the SUSE Build System.
Nevertheless, long-term historic data, which is very important for admins, still doesn’t exist. This makes ZFS potentially dangerous, in spite of all the advantages and its good reputation, because version 0.6 of the code, for example, still cannot offer format assurances.
If you are looking to compare filesystem speeds, you should not set too much store by absolute figures – that is, the net megabytes per second (MBps) in the graphics or the run times in the benchmarks – because the values depend too greatly on the specific hardware in use.
A direct comparison between the candidates is much more definitive, especially for sequential or random read and write operations. Making these measurements is the task of IOzone; Figures 1-4 show the most important results. The complete set of raw data and the scripts are available online.
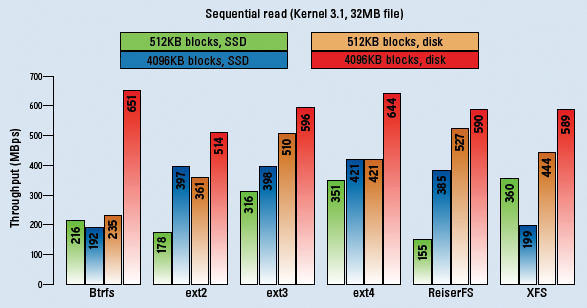 Figure 1: Sequential reading is the domain of classic hard disks. In a RAID array, they sometimes deliver more than 650 MBps; ext4 won this comparison.
Figure 1: Sequential reading is the domain of classic hard disks. In a RAID array, they sometimes deliver more than 650 MBps; ext4 won this comparison.
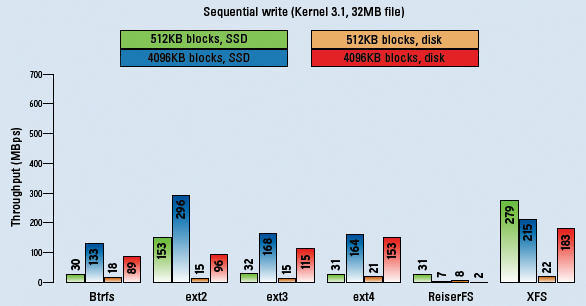 Figure 2: In the sequential write test, XFS clearly had its nose in front, both on SSD and on HDD. Ext2 was only better with 4096-byte-sized blocks. Compared with this, ReiserFS revealed major weaknesses.
Figure 2: In the sequential write test, XFS clearly had its nose in front, both on SSD and on HDD. Ext2 was only better with 4096-byte-sized blocks. Compared with this, ReiserFS revealed major weaknesses.
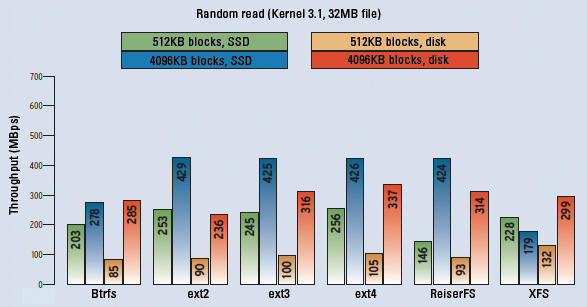 Figure 3: Random read (i.e., reading from randomly selected blocks) is difficult for hard disks. Mechanical positioning of the heads slows them down; just two SSDs is all it takes to overtake them.
Figure 3: Random read (i.e., reading from randomly selected blocks) is difficult for hard disks. Mechanical positioning of the heads slows them down; just two SSDs is all it takes to overtake them.
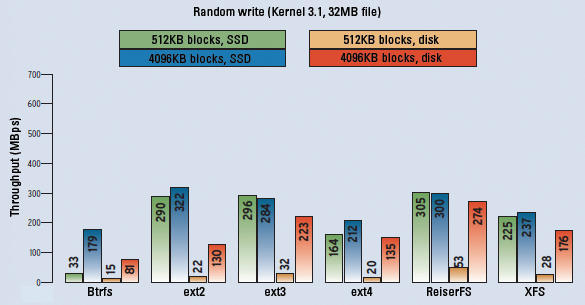 Figure 4: Random write combines the weaknesses of traditional hard disks. SSDs take the lead; Btrfs has major weaknesses in the case of small blocks, and ReiserFS surprises with good values.
Figure 4: Random write combines the weaknesses of traditional hard disks. SSDs take the lead; Btrfs has major weaknesses in the case of small blocks, and ReiserFS surprises with good values.
All Buffers Off!
To ensure that no unwanted optimizations by buffers or caches on the test system distorted the results, adding different levels of variance depending on the filesystem, I disabled both the RAID controller cache and all the HDD caches. Additionally, before each test, I ensured that the Linux kernel itself had no chance to perform any optimizations by serializing I/O operations through buffers and caches. To do this, I ran sync and doubly deleted the page cache, inodes, and dentries (with echo 3 > /proc/sys/vm/drop_caches).
The benchmark script prepared each filesystem for the benchmark run with the appropriate mkfs tool (on ZFS, this was zpool) without further options. Also, the countless possibilities for optimization were ruled out in the tests (e.g., btrfs -o SSD can increase the throughput in individual cases by up to 30 percent).
In addition to the IOzone tests, I performed a long series of my own benchmarks, including mkdir, touch, echo, cat, dd, rm, and rmdir in long loops with meaningful values.
Ranking and Kernel Test
If you simply assign points on an equal footing for placement in each of the many individual disciplines, you receive interesting results: XFS scores 56 points ahead of ReiserFS and ext4, followed by Btrfs and ext2. If you consider only the more atomic tests from Bash scripts, XFS is still in the lead ahead of Btrfs and ReiserFS.
In the IOzone benchmark results, which are based exclusively on data throughput, however, ext3 wins by a large margin (32 points), with ReiserFS (26), XFS (25), and ext4 (24) lagging a bit behind.
As Figures 5 and 6 show, migrating to the latest kernel doesn’t always mean benefits.
 Figure 5: The new kernel 3.3.6 doesn’t automatically mean an improvement in throughput with SSDs. In the IOzone measurements, only ext2 and XFS exhibit better values than with kernel 3.1.10 in various tests.
Figure 5: The new kernel 3.3.6 doesn’t automatically mean an improvement in throughput with SSDs. In the IOzone measurements, only ext2 and XFS exhibit better values than with kernel 3.1.10 in various tests.
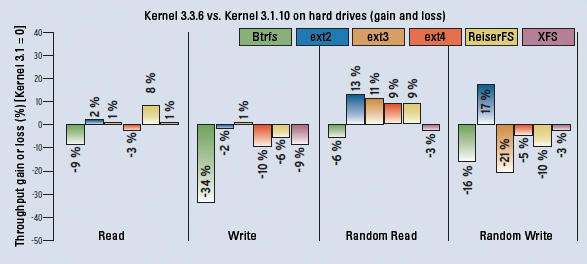 Figure 6: Running on classical disks, the candidates failed to perform better on the new kernel than on its predecessor. It was only in random read that the ext systems scored points.
Figure 6: Running on classical disks, the candidates failed to perform better on the new kernel than on its predecessor. It was only in random read that the ext systems scored points.
In a test with kernel 3.3.6 (current when this issue went to press) on SUSE Tumbleweed, performance in almost all filesystems declined compared with kernel 3.1.10. The ext filesystems only benefited in the random read discipline. In all other disciplines, the filesystems performed more poorly with kernel 3.3.6 than kernel 3.1.10.
Ext-ra Special: XFS
XFS is obviously still a good choice despite its age. On SSDs and HDDs, it delivers fast atomic actions and stable values in the IOzone benchmark. Larger files seem to be a problem. Another interesting result is that XFS seems to have improved on SSDs between kernels 3.1.10 and 3.3.6.
Taking the silver medal, ext3 impresses in the IOzone benchmark. In contrast, the filesystem is not so good at handling atomic file system operations. Ext4 was clearly better, but, unfortunately, at the expense of throughput, which explains why ext4 only took bronze in the overall standings. The legacy ext2 impresses with its performance in random write and is one of only a few to benefit from the new kernel 3.3.6.
ReiserFS performed very well on average, achieving stable values in the atomic filesystem operations. However, its sequential write performance is disconcerting: It was several hundred percent behind all the other candidates, and, although this is not reflected directly in the points score, it could very well be a problem in everyday life.
ZFS on Linux is merely another tail-ender; however, it is the undisputed leader on both kernel versions when it comes to sequential writing of large blocks in large files. In contrast, Btrfs was not only the filesystem to suffered the most on the new kernel (up to 40 percent less throughput), it proved to be a disappointment overall. The young system only set high standards in sequential reading from HDDs.
SSD or HDD?
Regardless of filesystem, the difference between SSD and HDD throughput rates for writing and, even more so, in random tests is significant. This finding confirms the recommendation to use SSDs for systems with high random read/write traffic, regardless of the filesystem because they do not suffer from the mechanical latencies that slow down hard drives.
In the test scenario here, just two SSDs was all it took to outperform a RAID array with six disks. The throughput in random write operations was, in some cases, almost three times that of the hard disks. That said, however, traditional disks in a RAID were able to match SSD performance in terms of sequential transfer rates.
Info
[1] Transtech Lynx Calleo Application Server
The Author
Michael Kromer is Head of Professional Services, Germany, with Zarafa. Among other things, he is responsible for Zafara’s large-scale implementations and architectures. In his free time, Michael is involved in various open source projects (e.g., the Linux kernel, OpenNX, Asterisk, VirtualBox, ISC BIND, and openSUSE) and all kinds of virtualization technologies and processor architectures.
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs
-
Juno Computers Launches Another Linux Laptop
If you're looking for a powerhouse laptop that runs Ubuntu, the Juno Computers Neptune 17 v6 should be on your radar.