How compilers work
Meticulous Transformer

Compilers translate source code into executable programs and libraries. Inside modern compiler suites, a multistage process analyzes the source code, points out errors, generates intermediate code and tables, rearranges a large amount of data, and adapts the code to the target processor.
Below the surface, a black box compiler handles complex processes that require good knowledge of machine theory and formal languages. Given the importance of compilers, it is not surprising that compiler construction is standard curriculum for computer science students. If you have never been to a college-level lecture on compiler theory – or if you went to the lecture but need a refresher course – this article summarizes the basics. (See the box titled "Teaching Material for Compiler Construction.")
In simple terms, a compiler goes through three steps: It parses the source code, analyzes it, and synthesizes the finished program (Figure 1).
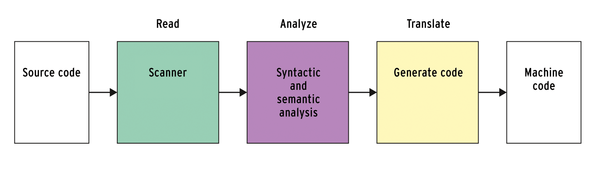 Figure 1: Rough structure of a compiler: parse code, analyze it, and create an executable program.
Figure 1: Rough structure of a compiler: parse code, analyze it, and create an executable program.
[...]