Tools for generating regular expressions
Pattern Seekers

© Photo by JJ Ying on Unsplash
As regular expressions grow in complexity, regex generators can make the job easier by computing the patterns for you.
A regular expression (regex) [1] is a sequence of characters that describes a search pattern. You can use a regex to save time searching and replacing in texts, such as strings in programming languages, database query results, or normal documents. Regexes also can help you effectively use utilities, such as grep [2], xmlgrep [3], and ugrep [4].
Ultimately, a regex's usefulness depends on the pattern you select. Formulating a regex that delivers precise results is no easy task (see the "DIY Regular Expressions" box). To save time, a regex generator can automate this step for you by taking a text/character string and deriving a suitable regular expression.
DIY Regular Expressions
While formulating a regular expression can take some time, especially for newcomers, it is worth the effort if you want faster results. Regular-Expressions.info [5], Regex DB [6], and Mastering Regular Expressions [7] all clearly explain strategies for creating regexes and provide a huge number of examples to show how useful regexes can be.
For instance, you can use a regular expression to test whether a credit card number entered on a website form is in the correct format. Figure 1 shows a regular expression for numbers on Visa credit cards: the number 4 followed by any three digits, then a separator (nothing, a space, or a hyphen), followed by up to three blocks of any four digits, which can again be followed by a separator. This regular expression does not validate the card, but it reliably filters out incomplete numbers and identifies typing errors.
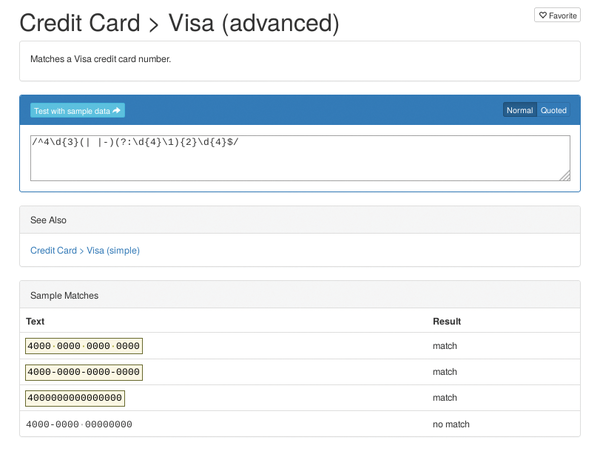 Figure 1: Regular expressions offer a relatively easy approach to validating the structure of a Visa card number.
Figure 1: Regular expressions offer a relatively easy approach to validating the structure of a Visa card number.
The RegEx101 wiki [8] also has a good reputation for testing your regular expressions. Not only does RegEx101 support different regex dialects, but it also shows you which patterns match and provides an explanation. Figure 2 shows a RegEx101 test for dates, where the individual components (day, month, and year) are given as decimal values separated by hyphens.
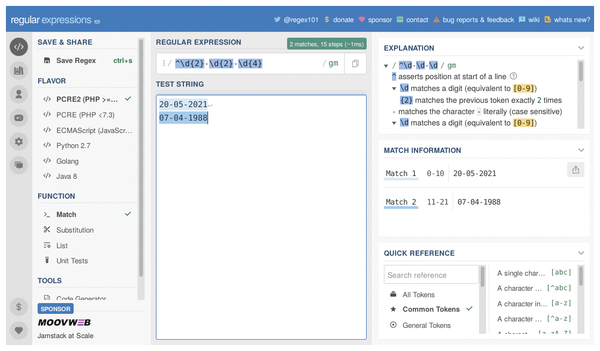 Figure 2: RegEx101 checking date input.
Figure 2: RegEx101 checking date input.
Regex generators work with varying degrees of precision. Some regex generators offer maximum precision, where the regular expression finds exactly one pattern. Others offer minimum precision, where the regex finds a set of patterns with a similar structure. In this article, I test several regex generators to determine how well they work (see also the "Nonfunctional" box).
Nonfunctional
During testing, I came across two projects, txt2re [9] and grex [10], which each offered a good approach in theory but ultimately did not generate usable results.
The private website txt2re, developed by Mark James Ennis, works similarly to Regex Generator. Ennis's dislike of regular expressions led him to try to automate the process as much as possible. Unfortunately, txt2re currently only works with the default text string 20:Apr:2016 This is an Example!, making the tool only useful for demonstration purposes. It remains unclear whether the limited functionality is due to the web browser or the JavaScript used.
Grex v1.2 is based on Mozilla's Rust programming language and the JavaScript-based regexgen [11] tool. While grex is currently available for download from its GitHub project page, my attempt to compile grex from the sources on Debian 11 failed.
Olaf Neumann's Regex Generator
Regex Generator [12], which is implemented in Kotlin and JavaScript, lets you create regular expressions via Olaf Neumann's website. The website offers several input boxes. First, you enter the text string for which you are searching. As an example, I used a typical log entry consisting of a date and a message, both separated by a space.
From your entered text in box 1, the software derives the individual components, which it highlights in different colors (shown in box 2). You then select the relevant component by clicking on the respective color or component. The component is then colored gray. Regex Generator then generates the appropriate regular expression from your selection and displays it in box 3 (Figure 3).
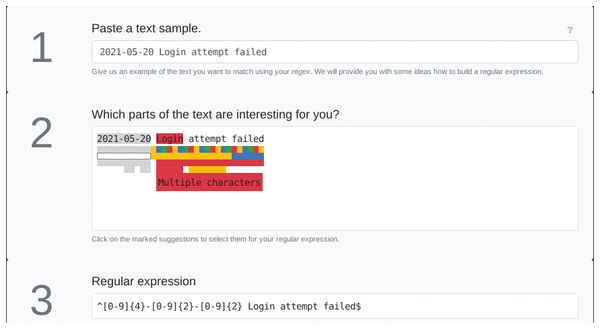 Figure 3: After entering the desired text string and selecting the components in Neumann's online Regex Generator, the appropriate regular expression is returned.
Figure 3: After entering the desired text string and selecting the components in Neumann's online Regex Generator, the appropriate regular expression is returned.
You can then select the programming language where you will use the regular expression. Currently, you can choose between several languages, including PHP, Ruby, and JavaScript (Figure 4).
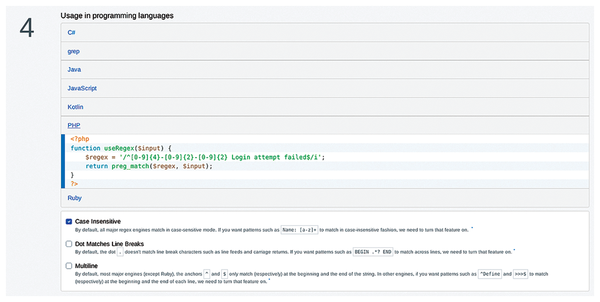 Figure 4: After selecting the desired programming language, Regex Generator displays a regular expression (shown here as a PHP function).
Figure 4: After selecting the desired programming language, Regex Generator displays a regular expression (shown here as a PHP function).
In terms of precision, Regex Generator provides moderate accuracy. The date matches any data, but the text only matches the error message Login attempt failed in upper and lowercase thanks to the /i parameter at the end of the regular expression. Consequently, Regex Generator is adequate if you just want to search for failed logins for arbitrary dates, for example.
rgxg
ReGular eXpression Generator (rgxg) [13] generates regexes from the command line (Figure 5). You can find rgxg in the Debian, Ubuntu, and Linux Mint repositories and install it using familiar on-board tools. For better output readability, you should use rgxg in a terminal window with a dark background.
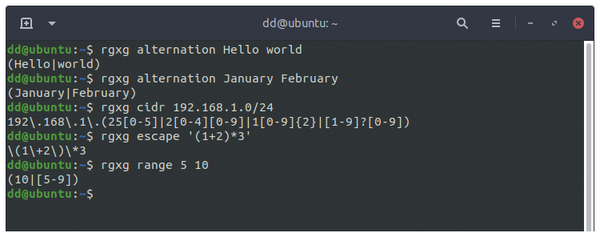 Figure 5: Regular expressions generated by the rgxg command-line program.
Figure 5: Regular expressions generated by the rgxg command-line program.
In practice, rgxg expects a call with different subcommands (see Table 1).
Table 1
rgxg Subcommands
| Subcommand | Description | Example | Generated Expression |
|---|---|---|---|
| alternation |
Generates an expression to match each of the stated patterns |
rgxg alternation January February |
(January|February) |
| cidr |
Generates an expression to match all addresses in a CIDR block (IPv4) |
rgxg cidr 192.168.1.0/24 |
192\.168\.1\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9]) |
| escape |
Escapes a string |
rgxg escape '(1+2)*3' |
\(1\+2\)\*3 |
| range |
Generates an expression to match the stated range |
rgxg range 5 10 |
(10|[5-9]) |
In addition, rgxg offers a whole range of parameters to further refine the generated expressions (see Table 2).
Table 2
rgxg Parameters
| Parameter | Description | Example | Generated Expression |
|---|---|---|---|
| range -N |
No outer brackets |
rgxg range -N 5 10 |
10|[5-9] |
| range -z |
Only numbers with leading zeros |
rgxg range -z 0 31 |
(3[01]|[0-2][0-9]) |
| range -z -m |
Only figures with a certain number of leading zeros |
rgxg range -z -m 4 0 31 |
(003[01]|00[0-2][0-9]) |
In terms of accuracy, rgxg offers maximum precision thanks to the parameters that let you generate a regular expression that exactly matches the given pattern.
txt2regex
Another command-line option, txt2regex [14] is a shell script with keyboard-based menu control. Like rgxg, you will find txt2regex in the repositories of most recent distributions, such as Debian or Fedora. On macOS, you can use Fink [15] for the install.
Due to the user interface's color scheme, you will want to use txt2regex in a terminal with a dark background. Alternatively, use the --nocolor parameter to switch off the color or --whitebg to switch to a suitable display for a light background. When txt2regex is running, typing an asterisk will toggle the display.
Txt2regex offers a helping hand when generating regular expressions by asking questions about the characters, including how many characters follow each other. Based on the input, txt2regex assembles the expression for various tools, such as awk, find, grep, PHP, and PostgreSQL.
You can access a complete list of dialects by typing a forward slash. You then select the corresponding letter from the list (Figure 6) to generate the regular expressions in the desired dialect (Figure 7).
 Figure 6: Txt2regex supports a large number of dialects for regular expressions.
Figure 6: Txt2regex supports a large number of dialects for regular expressions.
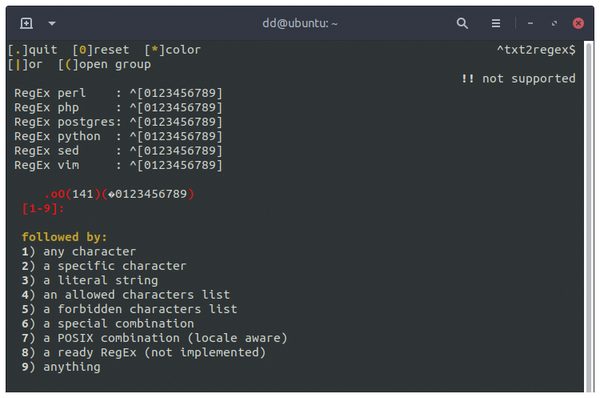 Figure 7: Txt2regex generates patterns for the selected dialects. This is an intermediate step in querying for the desired string.
Figure 7: Txt2regex generates patterns for the selected dialects. This is an intermediate step in querying for the desired string.
Txt2regex requires precision. As you use txt2regex, you will learn to specify the pattern sequence precisely. Txt2regex provides an overview of how you need to specify the regular expression in the respective tool for it to recognize the pattern. This is a big help because various implementations and dialects are found in everyday Linux: regular expressions, extended regular expressions, and Perl-Compatible Regular Expressions (PCRE).
Like rgxg, txt2regex formulates regular expressions with maximum precision by using parameters to adapt the expression to your specified pattern.
RegexGenerator
In looking for libraries that work similarly to the other tools discussed in this article, my research turned up limited results. For Python, I found RegexGenerator [16] and its associated regex-generator-lib [17].
Listing 1 shows a short script for RegexGenerator, which determines a regular expression for the string 415-5553-7676. You can then save and run the regular expression as rg.py (Listing 2). The generated regex shown in Listing 2 does the trick: a pattern consisting of three digits, followed by a minus sign, four digits, another minus sign, and another four digits.
Listing 1
RegexGenerator Script
from RegexGenerator import RegexGenerator
myRegexGenerator = RegexGenerator("415-5553-7676")
print(myRegexGenerator.get_regex())
Listing 2
rg.py
$ python3 rg.py
\d{3}[-]\d{4}[-]\d{4}
However, this generated regex lacks precision. Not only does it match the above string, but it also matches other strings, such as 123-4567-8901 or foo-123-5553-7676-bar. According to this regular expression, the digits can be arbitrary and the pattern can include other characters because the regex does not use delimiters such as \b for word boundary, ^ for beginning of line, and $ for end of line.
Instead, A regex of ^415\-5553\-7676$ would be more precise and easier to read, resulting in the three digits 415 followed by a minus sign, three times the number 5 followed by a 3, another minus sign, and then two times the sequence of digits 76 including characters for the beginning of the line (^) and the end of the line ($).
rex
If you use the rex tool from Python's Test-Driven Data Analysis (tdda) package [18], there is a very neat, practical use case. The example shown in Listing 3 determines the regular expression for naming image files. All of the file names start with the three letters DSC, followed by five numbers, a period, and the three letters .JPG.
Listing 3
rex from tdda
$ ls images/*.JPG
DSC06743.JPG
DSC06745.JPG
DSC06751.JPG
DSC06754.JPG
$ ls images/*.JPG | python3 tdda/rexpy/rexpy.py
^DSC\d{5}\.JPG$
The regular expression is correct, as far as it goes; it also includes two additional delimiters, ^ for beginning of line and $ for end of line. The regex excludes false positives as long as the pattern consists of the three uppercase letters DSC followed by any five sections and the strings .JPG. However, a more precise regular expression would be DSC067((4[35])|(5[14]))\.JPG.
Again, the results returned by rex from the tdda library end up in the middle of the pack in terms of precision. While rex successfully matches the DSC and JPG portions of the pattern, it can produce a false positive for the digits in the sequence.
RegExTractor
To demonstrate the capabilities of RegExTractor [19], another Python regex extractor, I used random German license plates. Listing 4 first outputs the license plates followed by the regular expression that matches all license plates.
Listing 4
Running RegExTractor
$ python main.py
Kennzeichen:
A-BC 1234
CB-LN 5246E
FR-CG 1554
TUT-R 712
AA-LN 5E
The regex for this:
[A-Z][A-Z]{0,2}\-[A-Z][A-Z]?\ [0-9][0-9A-Z]{1,4}
However, the regular expression that RegExTractor outputs is not correct. In particular, the last partial pattern of [0-9][0-9A-Z]{1,4} allows any digit followed by a combination of one to four capital letters and digits.
A more accurate solution would be the subexpression [0-9]{1,4}E+ for one to four digits, followed only by the capital letter E for electric cars. In testing, this problem occurred repeatedly. Consequently, I cannot recommend RegExTractor.
Conclusions
Deriving regular expressions based on existing text fragments and patterns helps to analyze and recognize similarities in more complex patterns. The tools I tested work well but not always without error. Some tools generated regular expressions that were more generic than they actually should be based on the text fragments, resulting in searches that returned more matches than desired. In particular, these tools may include results that don't actually match the search patterns, resulting in false positives and some fuzziness.
Regular expressions are complex, inherently mapping a fragment and pattern differently. The performance of these tools does deserve credit given the complexity of the tasks. For these generators to be more useful in the future, increased precision would be desirable.
Acknowledgement
The author would like to thank Axel Beckert and Arne Wichmann for their help and critical comments during the preparation of this article.
Infos
- Regular expression: https://en.wikipedia.org/wiki/Regular_expression
- grep everything: http://noone.org/blog/English/Computer/Shell/grep%20everything.futile
- xmlgrep: https://linux.die.net/man/1/xmlgrep
- "Search more efficiently with Ugrep" by Karsten G¸nther, Linux Magazine, issue 245, April 2021, https://www.linux-magazine.com/Issues/2021/245/Tracked-Down/(language)/eng-US
- Regular-Expressions.info: http://www.regular-expressions.info/
- Regex DB: https://rgxdb.com/
- Friedly, Jeffrey. Mastering Regular Expressions, O'Reilly Media, Inc., 2006: http://regex.info/book.html
- RegEx101: https://regex101.com/
- txt2re: http://www.txt2re.com/index_php3.html
- grex: https://github.com/pemistahl/grex
- regexgen: https://github.com/devongovett/regexgen
- Regex Generator by Olaf Neumann: https://regex-generator.olafneumann.org/
- rgxg: https://rgxg.github.io/
- txt2regex: https://aurelio.net/projects/txt2regex/
- Fink: https://www.finkproject.org/
- RegexGenerator: https://github.com/dbuhlbrown/Regex-Generator
- regex-generator-lib (Python): https://pypi.org/project/regex-generator-lib/
- tdda: http://www.tdda.info/
- RegExTractor: https://github.com/iuliux/RegExTractor