Bulk renaming files with the rename command
Names Have Been Changed

© Photo by CHUTTERSNAP on Unsplash
The rename command is a powerful means to simultaneously rename or even move multiple files following a given pattern.
Users often have to rename a collection of related files according to a specific pattern. You might have logfiles with dates and times in the file name, but the dates are not written in your preferred format (20230315 instead of 15-03-2023). Perhaps you have a collection of digital photos from your camera, or maybe you are working with files created on an old Microsoft Windows or MS-DOS system that are all uppercase, and you want to give them more readable file names.
Changing the names of a few files by hand may be manageable, but changing more than a dozen files quickly becomes not only tedious but error-prone. Linux does have some tools that will rename files in bulk. Most notably, the Thunar file manager [1] has a very flexible Bulk Rename tool (Figure 1), with several powerful built-in pattern-matching criteria from which to choose, making the tool sufficient for most use cases.
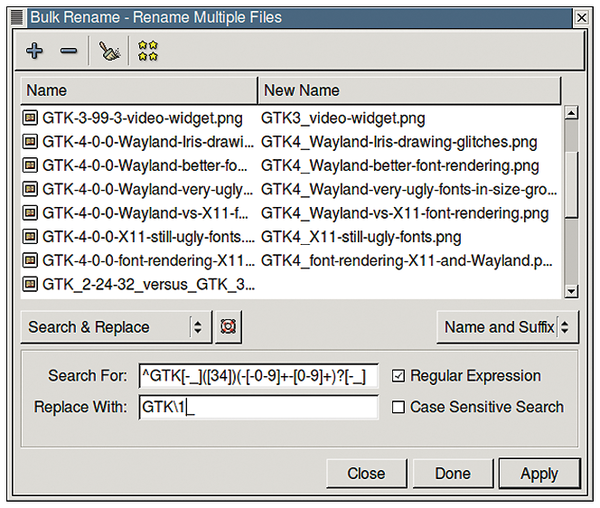 Figure 1: The Bulk Rename tool features many advanced capabilities, but it may not be as efficient as a command-line tool in the hands of an experienced user.
Figure 1: The Bulk Rename tool features many advanced capabilities, but it may not be as efficient as a command-line tool in the hands of an experienced user.
[...]