Choosing an open source database management system
Choices

© Lead Image © ioannaalexa, 123RF.com
Open source database management systems offer greater flexibility and lower costs while avoiding vendor lock-in. Finding the right one depends on your project's needs.
We live in a digital age where data is king. To efficiently manage that data, you need a database management system (DBMS). A DBMS lets you store, retrieve, and manipulate your data. It functions as a mediator between the database, applications, the developer, and the user interface (Figure 1). You can use a DBMS for simple data storage and retrieval or for more complex data-driven tasks.
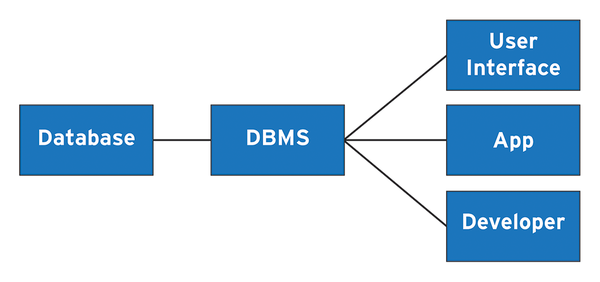 Figure 1: A DBMS acts as the middleman between your database and your end users.
Figure 1: A DBMS acts as the middleman between your database and your end users.
When it comes to choosing a DBMS, you may be overwhelmed with options. A quick Google search pulls up dozens of DBMS solutions. You'll find open source and closed source solutions. Some DBMSs use SQL to structure their data, while others go the NoSQL route. Finally, some DBMSs are better suited for enterprise environments.
To narrow the field, you need to consider your project's data management needs. In this article, I will explain the advantages of an open source DBMS solution, break down the differences between SQL and NoSQL DBMSs along with some examples of each type, and provide some criteria for choosing a DBMS. Let's get started.
Why Open Source
The first thing you should consider in selecting a DBMS is whether to use closed source or open source software. With closed source (proprietary) software, access to the source code is restricted. Open source software, on the other hand, gives the user the right to freely use, modify, and share the source code.
Proprietary solutions are not without benefits. Sometimes a proprietary DBMS offers a unique solution that happens to fit your needs. A vendor might offer 24/7 support from a single source or build protection for added security. However, all of this comes at a price and can result in vendor lock-in, limiting your ability to evolve to meet changing business needs.
An open source DBMS solution, on the other hand, offers many benefits, including greater flexibility, lower cost, no vendor lock-in, faster innovation, quality control, and data portability.
An open source DBMS is also more cost effective. By its nature, it is free to download. You also avoid licensing or registration fees for reusing, modifying, or distributing the software, and you won't be surprised by potentially rising renewal costs when your proprietary software subscription comes due.
You can also sidestep vendor lock-in with an open source DBMS. You won't be forced to purchase bundled technology that doesn't meet your needs. And if those needs change, you are free to redesign your system. With an open source DBMS, you can easily scale up or scale down to respond to environmental changes. In addition, you are free to try out new open source apps without affecting your budget.
You will find open source DBMS solutions at work in a wide range of industries, including e-commerce, healthcare, government, nonprofit organizations, financial services, and the high-tech field.
Common DBMS Types
While there are several types of DBMSs, the two most common are relational DBMSs (RDBMSs) and non-relational DBMSs. An RDBMS stores data in a highly structured format. Most RDBMS systems today use Structured Query Language (SQL) to store and manage the data. A non-relational DBMS, more commonly known as a NoSQL DBMS, handles less structured data. Both have their strengths and weaknesses. Ultimately, your project's data will dictate which type will provide the best solution.
SQL DBMSs
Used as back-end data systems for decades, SQL DBMSs are the most commonly used type of DBMS. An SQL-based RDBMS implements a predefined strict schema, which defines how the data is organized (including logical constraints such as table names, fields, data types, and relations). With a focus on consistency and availability, an RDBMS works best for data that is structured and related.
Data in an RDBMS is stored in tables consisting of rows (or records) and columns (or record attributes). Each table represents a relation with the rows holding individual records that pertain to that relation. You can connect one table to another using either a primary or foreign key relationship. A primary key functions as a unique identifier for each row (aka record) in a given table to prevent records from having the same value. A foreign key lets you link tables; it is a column or set of columns in one table that references a primary key in another table. By combining rows from two or more tables based on a shared related column, you can perform complex joins.
To ensure that database transactions (defined as a series of operations) are processed reliably, an RDBMS maintains Atomicity, Consistency, Isolation, and Durability (ACID) compliance. ACID compliance is an all-or-nothing approach – either all changes within a transaction are committed or none of them are. If a transaction is ACID compliant, you are guaranteed that a database is consistent before and after the transaction. Mission critical applications in particular require ACID compliance.
Most RDBMSs scale vertically, with the data residing on a single server. To scale up, you can add more power to the server (CPU, GPU, RAM), but scaling usually requires downtime because you have to take the server offline to make any upgrades. You can scale an RDBMS horizontally, where the data is spread or shared over multiple servers, but it is a much more difficult process. The complexity of maintaining ACID compliance and managing distributed transactions and joins can require data structure changes along with other design considerations.
Optimized for speed, RDBMSs offer fast SQL queries. They perform well for intensive read/write operations on small to medium datasets, but performance can begin to suffer if the number of user requests or the amount of data grows. To improve data retrieval speed, you can add indexes to data fields to query and join tables.
If you have highly structured data that doesn't change frequently, an RDBMS is a good choice. It offers a higher degree of data integrity, is able to handle complex queries, and is a better choice for transaction-oriented systems thanks to its ACID compliance. Examples of open source RDBMSs include MySQL, MariaDB, PostgreSQL, Firebird, and CUBRID.
MySQL
MySQL [1] was initially released in 1995 and acquired by Oracle in 2010. As part of the Linux, Apache, MySQL, PHP (LAMP) stack, MySQL is one of the more popular DBMSs. MySQL ranked second in the Databases category for all respondents on the 2023 Stack Overflow Survey and first for those learning to code [2].
Offering features typical of an RDBMS, MySQL uses a client/server system with a multithreaded SQL server, MySQL Server. MySQL Server supports different back ends, client programs and libraries, administrative tools, and APIs. It is a transaction-safe, ACID-compliant RDBMS that offers features such as full commit, rollback, crash recovery, and row-level locking.
MySQL has the advantage of being quick to install and easy to learn and manage. It is capable of handling a large volume of data and is compatible with most operating systems.
MySQL delivers high availability and disaster recovery thanks to its fully integrated replication technologies. To handle read scaling and report query offloading, MySQL relies on simple synchronous replication, while it uses asynchronous replication for high availability.
In terms of scalability, MySQL's native replication architecture lets it scale to meet demands. In fact, Facebook uses MySQL [1] to scale applications to meet its users' needs. You can also use MySQL as an embedded multithreaded library that you can link to standalone applications, making it smaller, faster, and easier to manage.
For security, MySQL uses built-in data masking and dynamic columns. It is popular with e-commerce, web-based transactions, data warehousing, and online transaction processing (OTP). It can even be used with some online analytical processing (OLAP) workloads.
MySQL Community Edition [3] is free and open source under a GPL license and boasts a large active community of open source developers, but it does not receive MySQL support. If you plan to embed MySQL in a commercial app, you will need a commercial license. The proprietary MySQL Enterprise Edition provides additional components for monitoring and online backup, high availability and security enhancements, and is built to interface with other enterprise-grade tools.
MariaDB
When Oracle acquired MySQL in 2010, MySQL founder, Michael Widenius, created MariaDB [4] as a fork of MySQL. Today, MariaDB has evolved beyond being a drop-in replacement to MySQL. It has added many new features, but it still maintains a high level of compatibility with MySQL. Consequently, most applications that work with MySQL work with MariaDB.
MariaDB supports modern SQL features such as common table expressions and temporal data tables. It also offers a large number of JSON functions to handle unstructured data [5]. Because MariaDB uses a dynamic thread pool, which allows threads to be retired, it benefits from improved speed, enhanced replication, and faster updates.
You can extend the MariaDB front end beyond pure transactional processing with pluggable storage engines from InnoDB, MyRocks, Aria, ColumnStore, and other third-party engines. With the MariaDB ColumnStore plugin, you can perform columnar analytics or hybrid smart transactions.
A Galera cluster engine allows for replication and state transfer. In terms of high availability, MariaDB MaxScale (available under a BSL license) can be used to provide a database proxy with failover and transaction replay capabilities.
MariaDB use cases include web and mobile apps, data warehousing, and data analysis. Companies such as Wikipedia, WordPress.com, and Google all use MariaDB.
MariaDB operates under a GPLv2 license and promises to remain open source. You can freely copy it into your project's local package repositories, which makes the deployment process easier and limits licensing obligations. MariaDB Community Server is free, but the subscription-based MariaDB Enterprise Server is recommended for production environments.
PostgreSQL
PostgreSQL [6], an object-relational DBMS (ORDBMS), is known for proven architecture, reliability, data integrity, a robust feature set, and extensibility. Originally part of the POSTGRES project at UC Berkeley, it has over 35 years of active development. In the Stack Overflow Developer 2023 Survey, it took first place in the Databases category among all respondents as well professional developers [2].
While PostgreSQL uses SQL, it extends the query language by adding features for safely storing and scaling complicated workloads. It conforms to the current SQL standard unless the standard contradicts traditional features or leads to poor architectural decisions. While most required SQL features are supported, they may have a slightly different syntax or function in PostgreSQL.
PostgreSQL can interact with both relational and object-oriented databases and offers features not traditionally available in RDBMSs. Because PostgreSQL supports complex objects, table inheritance, and additional data types beyond JSON, it can handle more complex workloads and schema designs. As a result, PostgreSQL can perform complex queries in a large database more quickly.
ACID-compliant since 2001, PostgreSQL achieves consistency through Multi-Version Concurrency Control (MVCC) and Write-Ahead-Logging (WAL). It offers asynchronous replication, failover, full redundancy, full-text database searches, and native support for JSON-style storage, key-value storage, and XML. In addition, you can customize PostgreSQL with plugins and extensions.
PostgreSQL scales well but has a heavier install footprint than MariaDB or MySQL. Use cases include complex data analysis, data science, AI-related capabilities, finance, manufacturing, and geographic information systems (GIS).
PostgreSQL is open source under the PostgreSQL License, which is similar to an MIT or BSD license.
Firebird
Firebird [7] offers concurrency, high performance, and language support for stored procedures and triggers. Based on InterBase 6.0 source code released in 2000 from Inprise (now the Borland Software Corporation), Firebird has been used in production systems under various names since 1981.
Supporting many ANSI SQL standard features, Firebird uses Procedural SQL (PSQL) as its internal language for stored procedures. It is 100-percent ACID-compliant and uses a multi-generational architecture (similar to MVCC) to ensure OTLP and OLAP operation. It offers careful writes that result in fast recovery with no need for transaction logs. With a small footprint, Firebird requires minimal configuration.
Firebird achieves high availability through optimistic locking at the record level, which reduces wait times. It adapts to fluctuating workloads and can be replicated to safeguard against disk failure. Online backups using snapshots allow for 24/7 operation.
You can scale Firebird in any direction with growth limited to available disk storage, which can be spread across multiple hard disks. With Firebird, the database engine manages the database's on-disk structure independent of the filesystem. You can embed the engine as a standalone client application, deploy it in a 2-tier client/server LAN with support for up to 750 users, or use it in a multi-tier system with thousands of users.
Firebird offers security via user authentication at the server level, SQL privileges within the database, optional database encryption via plugins, and wire protocol encryption between client and server.
Developed by a large community of independent C/C++ programmers, technical advisors, and supporters, Firebird provides documentation on their website along with community support through mailing lists [8].
With Firebird's Initial Developer's Public License (IDPL), you can build a custom version as long as any modifications are made available under an IDPL license, which enables other users to build on and use your modifications. An InterBase Public License (IPL) covers the source code inherited from InterBase, while the IDPL license applies to any additions or improvements made by the Firebird Project to the original InterBase code. There are no fees to download, register, license, or deploy Firebird "even for commercial developers."
CUBRID
Optimized for OTLP with fast query responses, CUBRID [9] offers enterprise-grade features that support distributed transactions and multiple replication methods.
To guarantee high availability, CUBRID relies on a simple single primary/secondary configuration to provide basic failover services. For intensive read scenarios, it uses a multi primary/secondary and primary/secondary/replica configuration.
If your software or hardware fails, WAL guarantees consistency and accuracy for restoring the database and online backup. CUBRID Backup options include hot/online as well as offline and incremental backups. You can even choose the level of backup you require.
You can scale CUBRID both vertically and horizontally with no limit on database size or number of tables, indexes, and rows. Even when the amount of data or queries increases, MVCC, lock-free hashes, row level and lock escalation, promotable read-to-write page latches, and other optimizations guarantee continued performance.
For security, CUBRID uses SSL/TLS to encrypt data between the client and the server and OpenSSL for server-side encryption.
The CUBRID engine has an Apache v2 license, with a BSD license for the CUBRID APIs and GUI tools.
NoSQL DBMSs
Non-relational, or NoSQL, DBMSs began to emerge in the late 2000s in response to decreased storage costs and increased data usage in applications. A non-tabular DBMS, NoSQL offers a more flexible schema, which makes horizontal scaling easier. As a result, NoSQL DBMSs can handle larger datasets and higher user loads, as well as allow for faster queries. They can handle ad-hoc organization and analysis of high volume data of disparate data types, allowing you to query specific information when you need it.
NoSQL DBMSs differ based on purpose. The four main types are:
- Document DBMS: Documents can vary in structure (they can even be incomplete), which leads to greater flexibility. You can embed other documents within a document. A document's fields function like columns in an RDBMS, and these fields can be indexed to increase search performance.
- Key-value stores: A simpler DBMS that associates a value with a key, which is then used to identify the object.
- Wide-column DBMS: Stores data in tables, rows, and dynamic columns and can use variable column names and formats across rows. This type of DBMS is good for quickly accessing columnar data. It can also store data across multiple machines to enhance security.
- Graph DBMS: Stores data in nodes (people, places, and things) and edges (relations to nodes). A graph DBMS maintains both data and relationships between data points, where the relationship is often just – if not more – important as the data itself.
If you have data that doesn't fit into a predefined relational mode, NoSQL DBMSs are the best choice for storing and processing that data. They work well with human- or machine-generated data in a text or non-text format. A NoSQL DBMS is also the best option for horizontal scaling, especially for cases where you want your data spread out over multiple geographic locations. Examples of NoSQL DBMSs include Apache Cassandra, MongoDB, Redis, JanusGraph, and CouchDB.
Apache Cassandra
A wide-column NoSQL DBMS, Apache Cassandra [10] offers high availability and scalability. Apache Cassandra started out as a Facebook project, but it became open source in 2008 as a Google Code project.
Apache Cassandra relies on a distributed DBMS that runs nodes across multiple machines and deploys easily across multiple clouds. Nodes are organized logically in clusters or rings, with the possibility of employing multiple data centers. Because Apache Cassandra uses a masterless architecture, any node can perform any function.
Lightweight and distributed, Cassandra enables ad-hoc organization and high volume analysis for diverse data types. It manages unstructured data with thousands of writes per second.
To guarantee high availability, Apache Cassandra replicates data to multiple nodes to achieve fault tolerance, with a choice of synchronous or asynchronous data replication. Cassandra also detects and recovers node failures, which ensures the database remains available.
Cassandra uses linear scaling, where resources are added sequentially. This guarantees consistent and optimal performance regardless of how many resources are added. Consequently, Cassandra works well with mission critical data. By using nodes, it allows developers to use off-the-shelf tools for scaling. In addition, by scaling horizontally, developers can use low commodity hardware. Finally, Cassandra promises no downtime when scaling. Cassandra is licensed under Apache v2.
MongoDB
MongoDB [11], a distributed NoSQL document DBMS, offers a flexible schema for storing data. It supports query on demand, secondary indexing, and real-time aggregation for accessing and analyzing data.
Each record in a MongoDB document is described in Binary JSON (BSON) format, which is optimized for space, speed, and efficiency. Developed by MongoDB, BSON encodes type and length information, making it quicker than JSON for traversals. It also adds some data types not found natively in JSON. However, applications can still retrieve the data in JSON format.
To achieve high availability, MongoDB uses replica sets, which provide redundancy and automatic failover.
MongoDB scales both vertically and horizontally, allowing it to handle large data loads. Its scale-out architecture lets many small machines work together, resulting in a faster system.
In 2018, MongoDB switched from an AGPL license to their own Server Side Public License (SSPL). Based on GPLv3, an SSPL license lets you use, review, modify, and redistribute the code, but it does put stipulations on using MongoDB as a service. A word of warning: The Open Source Initiative does not consider an SSPL license to be open source.
MongoDB is available as a free, self-managed Community Edition, as well as a commercial version, MongoDB Enterprise Advanced.
JanusGraph
As its name suggests, JanusGraph [12] is a scalable, distributed, NoSQL graph DBMS that lets you store and query graphs with hundreds of nodes and edges. JanusGraph was initially released in 2017 as a Linux Foundation project.
Thousands of concurrent users can use JanusGraph in real time to perform complex graph traversals. JanusGraph supports multiple storage back ends, including Apache Cassandra, Apache HBase, Google Cloud Bigtable, Oracle Berkeley DB, and ScyllaDB. Advanced capabilities such as full-text search are optionally available through third-party tools such as Elasticsearch, Apache Solr, and Apache Lucerne. JanusGraph can also support OLTP and OLAP with Apache Spark integration.
To ensure performance and fault tolerance, JanusGraph uses data distribution and replication. It also offers multi data center high availability and hot backups.
JanusGraph can scale to accommodate an increase in both data and users, but its scalability ultimately depends on the back end you use with it.
JanusGraph is totally free under an Apache v2 license.
Redis
Redis [13] is a key-value, NoSQL, in-memory store used as a DBMS. You can use Redis as a cache, a vector database, a document database, a streaming engine, or as a message broker. In its most popular use case, Redis can function as an enterprise-class session cache.
To handle caching, queuing, and event processing, Redis supports in-memory data structures (e.g., strings, hashes, sets, sorted sets, streams, etc.). You can program Redis using server-side scripting with Lua and server-side stored procedures with the Redis Functions API. You can also build custom extensions for Redis in C, C++, and Rust using a module API.
With Redis, your dataset is kept in memory for fast access. You can also persist all writes to permanent storage to protect against reboots and system failures. Redis supports asynchronous replication, and replication and automatic failover are available for both standalone and clustered deployments.
Clustering provides horizontal scalability in Redis with hash-based sharding. To grow a cluster, automatic repartitioning lets Redis scale up to millions of nodes.
Redis is licensed under a three-clause BSD license [14]. You can use, modify, and redistribute Redis in source and binary form as long as you include the provided copyright notice, list of conditions, and disclaimer. You also cannot use the names of Redis and its contributors to promote or endorse products derived from the software without prior written permission.
For documentation, community support, and mailing lists, see the Redis site.
CouchDB
CouchDB [15] from Apache, a NoSQL document-based DBMS, is a single-node DBMS that works behind the application server of your choice.
With a schema-free document model and built-in query engine, CouchDB can handle spikes in usage. It uses an intuitive JSON/HTTP API, supports binary data, and can be used on servers ranging from a Rasp Pi to a cloud installation.
The CouchDB Replication Protocol [16] makes Offline First apps possible. An Offline First app lets an organization perform some or all of its business logic without access to an Internet connection. This is particularly useful for mobile apps or any environment with an unreliable network infrastructure.
CouchDB is designed for reliability. Single nodes rely on a crash resistant, append-only data structure, while multi-node clusters use redundancy to make your data available whenever you need it.
You can easily scale CouchDB horizontally by adding more clusters to meet your demands.
CouchDB is licensed under an Apache v2 license. You'll find documentation, community chat channels, and mailing lists on the CouchDB website.
Making a Choice
Picking the right open source DBMS comes down to your project's unique data management needs. In making your decision, there are several things you should consider.
First, think about how your project uses data to determine which DBMS will provide the needed features, capabilities, and complexity. In terms of capacity, look at how data will flow through your database structure with particular consideration for the amount of data, storage needs, access requirements, and number of concurrent users. Another thing to consider is workload. Not only should you be thinking about your project's data types, query types, performance expectations, and business requirements, but also consider whether your workload is consistent or if it experiences event-driven changes. Finally, business needs change over time, so look for a DBMS that supports multiple use cases (not just your current use case) with no downtime. A rigid system with limited use cases may force you to migrate to a different DBMS in the future if your needs change.
In terms of scalability, determine whether a given DBMS can meet your organization's evolving data usage, customer needs, and compliance requirements over time. For enterprise-grade systems, it's particularly important to consider high availability and disaster recovery and whether a DBMS can scale to meet those demands. Also, don't rule out the need to scale down in the future.
In considering a DBMS, take a close look at its community support. A strong active community means developers are actively working to make stronger, more secure code. Because free open source DBMSs don't usually include tech support, look to see if the community supplies tutorials, forums, and documentation. In addition to being a good source of information, these resources will come in handy if you encounter any technical issues.
While open source is free, keep in mind that there may be associated costs with implementation. Most open source DBMSs charge extra fees for enterprise-grade plans and additional features. If you need more robust support than what is provided by the community documentation and forums, you may need to pay for the commercial version or contract with a third-party vendor.
In addition to cost, you should also consider the technical skills required to implement and maintain an open source DBMS. Do you have existing staff (with both the skills and the resources) to handle your chosen DBMS? If not, then you need to factor in whether you can afford to hire more staff or get outside help.
Two final things to consider are security and compatibility. When it comes to security, look for DBMS features such as secure logins, encryption, role-based access, control, and compliance. As for compatibility, you need to ensure that the new DBMS software works with the existing software and tools that your organization uses.
Enterprise Considerations
If you plan to use your DBMS in an enterprise-grade capacity, you'll need to consider a few additional criteria.
First and foremost, you want to look for a solution that promises stability. Depending upon how you'll use the distribution, ACID-compliance is particularly important for stability. For all use cases, a proven track record, a planned release cycle, high quality documentation, and support forums can provide assurance regarding the DBMS's longevity and community involvement.
For enterprise-grade systems, high availability is particularly important. Look for solutions that offer redundant and fault-tolerant components at the same location. And in case of a high availability failure, you'll want a solution with a disaster recovery plan to get your system back up and running.
Finally, you may need to consider paying for additional extensions or add-ons that can make an open source DBMS enterprise-grade. Most of the DBMSs highlighted here offer an enterprise version. You may also need to consider paying for outside 24/7 support from a third-party vendor if you don't have the staffing resources in house.
Conclusion
An open source DBMS can offer many benefits over closed source alternatives. With the right considerations, you can use these open source solutions in enterprise environments. To find the best one for your organization, a close look at your present and future needs will help you narrow down the field.
This article was made possible by support from Percona LLC, through Linux New Media's Topic Subsidy Program (https://www.linuxnewmedia.com/Topic_Subsidy).
Infos
- MySQL: https://www.oracle.com/mysql/what-is-mysql/#:~:text=the%20SQL%20syntax.-,MySQL%20is%20open%20source,code%20to%20suit%20your%20needs
- Stack Overflow 2023 Developer Survey: https://survey.stackoverflow.co/2023/#section-most-popular-technologies-databases
- MySQL Community Edition: https://www.mysql.com/products/community/
- MariaDB: https://mariadb.com/products/community-server/
- MariaDB JSON functions: https://mariadb.com/kb/en/json-functions/
- PostgreSQL: https://www.postgresql.org/about/
- Firebird: https://firebirdsql.org/en/about-firebird/
- Firebird support: https://firebirdsql.org/en/mailing-lists/
- CUBRID: https://www.cubrid.org/cubrid
- Apache Cassandra: https://cassandra.apache.org/_/index.html
- MongoDB: https://www.mongodb.com/try/download/community
- JanusGraph: https://janusgraph.org
- Redis: https://redis.io/
- BSD 3 clause license: https://opensource.org/license/BSD-3-Clause
- CouchDB: https://couchdb.apache.org/#top
- CouchDB Replication Protocol: https://docs.couchdb.org/en/stable/replication/protocol.html