
Natural language processing with neural networks
Lip-Synched

© Lead Image © lassedesignen, 123RF.com
If an actor's lip movements don't match the spoken text in a dubbed movie, it not only stresses people who are hard of hearing, but it can also make things difficult for everyone. AI can help solve this problem with lip-sync translations of movie scripts.
Automated natural language processing is an important field of artificial intelligence (AI) application. Natural language processing tasks range from text searches (such as web searches) to interaction with spoken language (such as with Siri, Alexa, or similar voice-controlled agents). Methods for intelligent language processing that go beyond the simple memorization and patterning of texts have been under development for more than 70 years. The famous Turing test [1] even considers the understanding and production of language to be a central criterion for AI.
Automated speech processing, along with speech recognition, is also one of the earliest applications for big data analytics. As early as 1952, Bell Laboratories' Audrey speech recognition system, for example, was able to set the parameters for each user such that the system recognized sequences of digits with a high degree of accuracy. Initially, this fine-tuning of the parameters had to be done manually. Automating this step takes us to machine learning, the process of adjusting model parameters based on training data.
The results of this machine learning are the models and their parameters. Accordingly, experts do not refer to AI, but instead to AI models. The widespread adoption of neural networks was a breakthrough for machine learning. Although their theoretical foundations were laid early on, more widespread use of neural networks initially required advances in computing power.
The individual neurons of the network each perform a small and relatively simple task. A neuron has no direct information about its neighboring, upstream, or downstream neurons. It acts like a small cog in a pocket watch; it has to be there to keep the watch ticking, but it does not measure time of its own accord.
The task of each neuron is as follows: It first totals the weighted inputs of the neurons upstream of it. The neuron's activation depends on whether this total exceeds a certain threshold. Instead of being proportional, this addition is non-linear, meaning that values far below the threshold result in a 0 and values above result in a 1. The behavior can be compared to that of classical transistors; it basically allows (sufficiently large) neural networks to compute any possible function.
Unlike transistors, however, activation is not abrupt, but continuous (there are also values between 0 and 1) and can therefore be differentiated. This allows the error costs that a neural network makes, for example, when classifying an image as "cat image" or "no cat image," to be converted to the individual parameters of the model (the weights of the inputs and thresholds for activating each neuron). To do this, you need to form the (partial) derivatives after each of the parameters, which tells you how changing the respective parameter influences the error.
The parameters are then adjusted slightly toward smaller errors and from there the error costs are recalculated, and so on. Error feedback (backpropagation) and adjusting the parameters toward smaller errors (gradient descent) ensure that the set of neurons can learn to solve a task in a combined way. Neural networks are trained by presenting them with pairs of inputs and expected outputs. You then adjust the model parameters bit by bit until the results have the lowest possible error costs.
Neurons in the neural network are organized in layers, much like visual processing in the brain. Although you can prove that theoretically a single inner layer is sufficient to approximate arbitrary functions, it has been shown that networks with more layers are often easier to train (Figure 1). This is where deep learning comes in. The boundary from shallow to deep is defined by corporate marketing departments and actually has no practical relevance.
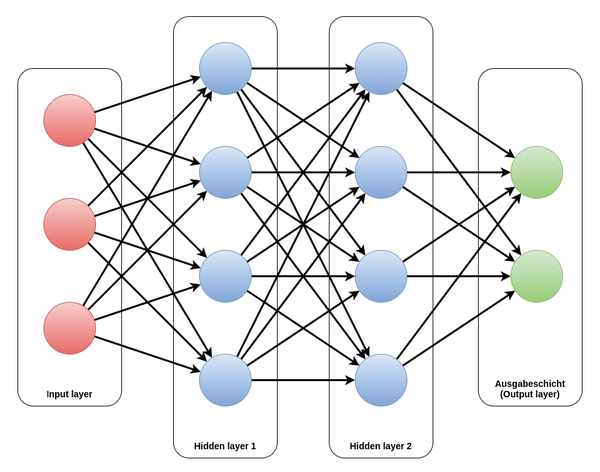 Figure 1: An example of a neural network with two inner layers. The (red) input neurons are activated to reflect the input. All subsequent layers each calculate their consequent activation based on the learned parameters. The result can be seen in the activation of the (green) output neurons.
Figure 1: An example of a neural network with two inner layers. The (red) input neurons are activated to reflect the input. All subsequent layers each calculate their consequent activation based on the learned parameters. The result can be seen in the activation of the (green) output neurons.
Either way, machine learning has thus far not tended toward creating artificial general intelligence (AGI) that behaves intelligently in all areas of the world (despite the claims of marketing departments). Instead, the capabilities in each case depend on the data with which the models were trained. The models are specialists, which is unsurprising: You don't expect a musician to be able to fix a car or a mathematician to make leaded glass windows.
But some models (such as the ones described in this article) are now trained with such a large and varied amount of data, as well as sometimes on different targets, that they may well give a superficial impression of intelligence.
Sequence Learning Problems
Natural language is characterized, among other things, by sentences consisting of different numbers of words, with the order of the words being critically important. This is even more complicated for spoken language. In the sentence "I didn't say we should kill him!," you can put the main stress on different words, and each time it will result in a different meaning. Check it out!
Language develops over time, in reading and writing, and even more so in listening and speaking. It's only natural that people process language word by word, unlocking the meaning bit by bit until they reach the end of a text. Some machine learning techniques have difficulty with sequence learning problems, for example, when faced with sequences of words (i.e., sentences) or letters (i.e., words).
Recurrent neural networks (RNNs) and their variants and derivatives are particularly well suited for sequence learning problems (see Figure 2). RNNs do not have a fixed number of inner neuron layers; instead, this number depends on the length of the input. Each layer processes one element of the input sequence, while also considering the preceding inner layer.
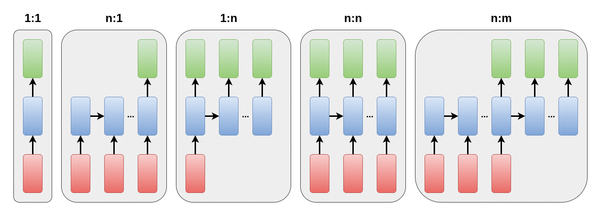 Figure 2: Possible sequence learning tasks that occur during speech processing. (Image modified from Karpathy, 2015 [2].)
Figure 2: Possible sequence learning tasks that occur during speech processing. (Image modified from Karpathy, 2015 [2].)
Unlike normal neural networks, the inner layers of an RNN share their parameters. An RNN can learn to grasp the shared meaning of the two words "scoop" and "ice" regardless of exactly where they are juxtaposed in the sentence. In fact, the contexts that the RNN can capture are not limited to adjacent words. It can – at least theoretically – learn to recognize arbitrarily complex and remote relationships.
RNNs can handle multiple variations of sequence learning problems. You can see the simplest case on the far left in Figure 2: a 1:1 relationship between input and output. It does not contain a sequence at all, but it is equivalent to the example shown in Figure 1.
The many-to-one architecture (n:1) is very common. It is used for classification and for instances where only the input is a sequence, among other things. In this way, for example, an input text can be assigned to a category in a given category system. The input here consists of a sequence of words and the output consists of the category to be determined. The process runs iteratively (from left to right in Figure 2) through the inner states (blue). The result (green) is based on the entire sequence of input words (red).
The opposite of the sequence learning problem is producing variable length output from fixed length input. This is desirable, for example, when generating texts, such as when you want to generate a weather forecast from a fixed number of measured values. This is where the one-to-many (1:n) architecture comes into play. After training, you use the model to determine the next word in the output sequence in each case (or to complete the output).
The first many-to-many architecture (n:n) shown in Figure 2 produces an output sequence that is as long as the input sequence. Among other things, this can be used to handle tagging tasks (e.g., tagging company names in texts). Another example would be tagging the departure and arrival train stations, dates and times, and other information that a user could provide when purchasing a train ticket.
Finally, the many-to-many architecture (n:m) on the far right allows inputs and outputs of different lengths, opening up a wide range of new possibilities that the n:n architecture does not offer. The question and the corresponding answer just happen to be the same length in Figure 2.
Texts often cannot be translated into another language with the same content if you are not allowed to change the number of words in the process. This model is known as an encoder/decoder model because it first encodes the input sequence into a representation of fixed length in line with the n:1 principle and then decodes it to form the output sequence. For long sequences, this results in a bottleneck because the model has to squeeze all the information through the fixed representation.
Extensions of the encoder-decoder model use attention control to recompute the attention over the intermediate steps of the input sequence after each step of decoding. This is very helpful, for example, for reliable translation from one language to another, because during encoding the main thing that needs to be captured is the overall meaning of the input sentence. What follows from this is whether, say, the German word bank should be translated as "bench" or "bank" in English. In addition, attentional control compensates for differences in sentence structure during decoding.
Listen and See
A special problem arises if you need to adapt a machine translation system with an encoder-decoder architecture to incorporate additional external knowledge into the translation process (Figure 3). This is necessary, for example, to create translations that can be optimally lip-synced. But first, let's explain why this is important.
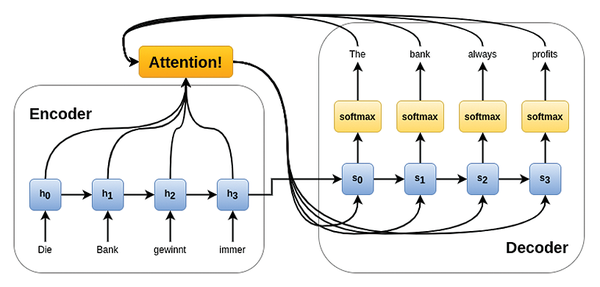 Figure 3: An n:m encoder-decoder model with attention control for end-to-end natural language to natural speech conversion.
Figure 3: An n:m encoder-decoder model with attention control for end-to-end natural language to natural speech conversion.
When people speak, the lips, jaw, and parts of the face move in a way that reflects the sounds that are produced. The upper and lower lips need to touch to produce M and B sounds, while A or O are spoken with the lips open. People who are hard of hearing use this in lip-reading to understand the content of what is being said without any (intelligible) sound. Even people with normal hearing always look at the speaker's lips and facial expressions and use that to understand what is being said – to a greater or lesser extent depending on the background noise.
The reverse phenomenon is known as the McGurk effect. If the visually perceived lip movements differ from what you hear, the visual impression will tend to override the auditory impression. "Gaga" is understood to be "Baba" in a movie where the speaker's lips close. Inappropriate lip movements not only lead to false perceptions, the cognitive dissonance between auditory and visual impression stresses the brain.
Movie translations therefore need to take into consideration that viewers will not just hear the speaker, but also see them. The translation needs to include lip movements so the dubbed film is as pleasant as possible to watch in the target language and to avoid artifacts caused by dubbing, such as phantom movements of the lips that spoil the viewing. Audiovisual translation of media is often intended to give the viewer the impression that the speaker in the image did not even have to be translated and dubbed, but that they actually spoke the text you can hear.
This means an additional constraint in the translation process because the visual channel also has to be considered. While translation is usually about finding a rendering that converts the content of a source text into the target language as faithfully as possible, audiovisual translation involves balancing content and the visual fit. First and foremost, audiovisual translations need to be of similar length. This can be difficult when words with the same meaning have different lengths in two languages (such as einzigartig in German, which translates to "unique" in English). In addition, you have to pay attention to the lip and jaw positions, at least as long as the speaker is in picture.
Figure 4 demonstrates this with an example from the television series Heroes. In the original English language version, the actor says "No, no, each individual's blood chemistry is unique, like fingerprints." It goes without saying that this word sequence precisely matches the visible movements. While a translation into German that is as faithful to the source as possible might now be a choice between individuellen Blutchemie (individual blood chemistry) or Chemie des Bluts jedes Menschen (chemistry of the blood of every human being), the chemistry bit was actually completely dropped in the lip-synced version. What German viewers hear at this point is "Nein nein, das Blut jedes Menschen ist einzigartig, wie Fingerabdr¸cke" ("No, no, each person's blood is unique, like fingerprints"), which matches the timing very well.
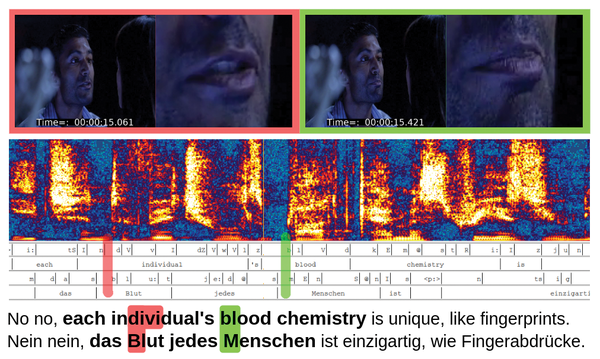 Figure 4: Maintaining lip synchronization in dubbing using the example of a short scene from Heroes, the US TV series.
Figure 4: Maintaining lip synchronization in dubbing using the example of a short scene from Heroes, the US TV series.
However, it's not perfect. At the point marked in green, the "M" is replaced by "Bl" in lip-sync. This is desirable because the two sounds can only be produced by the lips meeting. The situation is completely different with the area marked in red. While "divi" in the original version requires a perceptible opening of the lips, the "bl" which German viewers now hear can only be produced by closing the lips.
Minor deviations that occur rarely are not noticed by most viewers. In addition, prolonged and repeated viewing of dubbed material can cause viewers to become so familiar with it that they (often unconsciously) overlook this minor annoyance. However, if major lip-sync glitches reoccur in a movie or become too extreme (for example, if a character's voice is heard for seconds while their lips remain motionless), this drastically reduces the viewer's perception of the translation quality.
Lip-Synced Computer Translation
Extending the encoder-decoder model discussed earlier at a crucial point helps the model to generate translations that can subsequently be lip-synced. The lower part of Figure 5 shows the "dubbing estimator" that we developed. During automatic translation, the dubbing estimator reaches a compromise between a translation that is as faithful to the source as possible and a lip-synced translation that fits the movements in the best possible way.
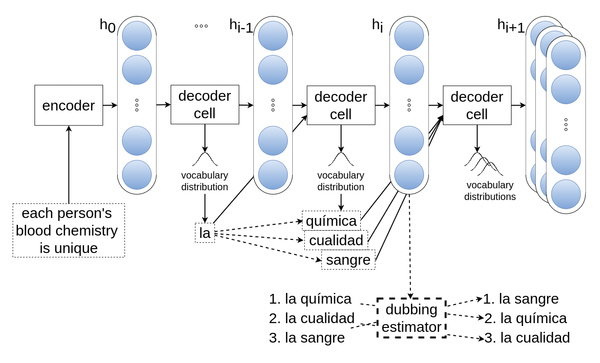 Figure 5: The encoder-decoder architecture extended by a dubbing estimator improves the synchronous speech of the translation.
Figure 5: The encoder-decoder architecture extended by a dubbing estimator improves the synchronous speech of the translation.
To do this, the dubbing estimator does two key things. It looks at the speech duration and syllable count in the source language and matches this with the estimated duration and syllable count in the target language. The dubbing estimator also balances the results of a video analysis of facial movements (and whether or not the speaker is actually visible) with expected movements when the translation is spoken. It is useful that the facial patterns (called visemes, which are speech sounds that look alike) are less strict than the sounds: P, B, and M look practically the same in the video.
The encoder in this system remains unchanged and is not shown separately in Figure 5 for this reason. However, during decoding, it is not only the word most likely to occur next in the translation that is created, but several words, and based on these, once again, a number of the most probable next words. The model sorts the resulting word sequences by their estimated translation quality: the best first and the worst last. The dubbing estimator now calculates the lip-sync quality for each candidate and weighs these two values together. Translations that are a poor match end up at the back of the list in order to achieve the best possible compromise between translation and dubbing quality.
We also ran our experiments with English-Spanish data, which is why Figure 5 shows Spanish words. You can see that la quìmica and la cualidad are initially the better translations, but in combination with the lip-sync quality they can't compete with la sangre. This results in the translation La sangre da cada indivìduo es ùnico, como una huella, which is a pretty good lip-sync candidate. In Spanish, it makes sense to shorten "blood chemistry" to create enough time for de cada indivìduo es ùnico.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
New Steam Client Ups the Ante for Linux
The latest release from Steam has some pretty cool tricks up its sleeve.
-
Gnome OS Transitioning Toward a General-Purpose Distro
If you're looking for the perfectly vanilla take on the Gnome desktop, Gnome OS might be for you.
-
Fedora 41 Released with New Features
If you're a Fedora fan or just looking for a Linux distribution to help you migrate from Windows, Fedora 41 might be just the ticket.
-
AlmaLinux OS Kitten 10 Gives Power Users a Sneak Preview
If you're looking to kick the tires of AlmaLinux's upstream version, the developers have a purrfect solution.
-
Gnome 47.1 Released with a Few Fixes
The latest release of the Gnome desktop is all about fixing a few nagging issues and not about bringing new features into the mix.
-
System76 Unveils an Ampere-Powered Thelio Desktop
If you're looking for a new desktop system for developing autonomous driving and software-defined vehicle solutions. System76 has you covered.
-
VirtualBox 7.1.4 Includes Initial Support for Linux kernel 6.12
The latest version of VirtualBox has arrived and it not only adds initial support for kernel 6.12 but another feature that will make using the virtual machine tool much easier.
-
New Slimbook EVO with Raw AMD Ryzen Power
If you're looking for serious power in a 14" ultrabook that is powered by Linux, Slimbook has just the thing for you.
-
The Gnome Foundation Struggling to Stay Afloat
The foundation behind the Gnome desktop environment is having to go through some serious belt-tightening due to continued financial problems.
-
Thousands of Linux Servers Infected with Stealth Malware Since 2021
Perfctl is capable of remaining undetected, which makes it dangerous and hard to mitigate.