
Life and times of the classic ext Linux filesystem
Jump to Ext3
By the turn of the millennium, ext2 had developed into a stable and widespread filesystem. Over time, however, ext2 had difficulty dealing with the growing volumes of data on ever-growing hard disks. Some developers, including Scotsman Dr. Stephen Tweedie, attempted some performance improvements and useful changes in the code.
However, the architecture of ext2 limited its evolution, which meant that it eventually made sense to move to a new version of the filesystem. Tweedie and other developers took the plunge and launched ext3, which was downwardly compatible to ext2.
One major innovation in ext3 was a feature that Tweedie had already developed in 2000 as an extension of ext2: the journal. This feature safeguards a filesystem against inconsistencies in case of a sudden crash (see box titled "Journaling with the Ext Filesystem"). Ext3 launched as a slightly improved ext2 with a journal.
Journaling with the Ext Filesystem
A change in the ext filesystem takes effect in many places: If a new file is added, the filesystem reserves blocks and an inode position. Additionally, ext creates an inode, writes the data, changes the last access time in the inode of the corresponding directory, and updates the statistics in the superblock. Also, the kernel does not write the data directly to the hard drive. It first keeps the data in memory but tells the software that the operation was completed. It is only after a specified interval that the kernel writes several changes to disk all at once using an optimized approach.
If an unforeseen event like a crash occurs before the data is written to the disk, the crash is likely to make the filesystem inconsistent. For example, it is not clear what data the kernel has actually written to the hard disk and what is only in temporary memory. At boot time or during mounting, the system therefore checks the filesystem. Depending on the size of the filesystem and speed of the medium, this test takes as long as one to two episodes of your favorite TV show. At worst, you then still need to perform a manual repair.
A journal makes tests of this kind superfluous: The filesystem spreads out a kind of safety net. Under ext3, the changes are not written directly; instead, the kernel first writes the information to the journal (a kind of log book). Depending on the configuration, the journal might only contain the metadata (e.g., the number of reserved blocks and all other non-user data) or metadata and user data. By default, many distributions only save the metadata for performance reasons.
After writing all the relevant changes to the journal, the operation (transaction) is deemed complete; a commit winds it up. At the next opportunity, the kernel now writes the changes to disk, which ensures a new, consistent state. The actual data is already on the hard drive in the default setting, but the system only references the data in the filesystem after the journal commit.
If a system crash occurs between writing the journal and committing the changes, the system only needs to transfer the transactions from the journal to the filesystem when checking the filesystem during the next boot.
However, for complete safety, you need to make sure that the system keeps the changed content in the journal. You define how the journal works when mounting the filesystem with mount -o data=<mode_name> (e.g., mount -o data=journal). However, the journal mode affects the performance of the filesystem, which is why it is not enabled by default, although it provides the best safety.
The most used journal mode is ordered (often the default), which initially writes the contents to the filesystem and only then updates the metadata in the journal (Figure 4). The third mode, writeback, only writes the metadata to the journal and leaves it to the kernel to decide when it writes the content to the HDD.
Depending on the configuration, a filesystem journal offers quite good insurance against system crashes. The journal also can be swapped out to another storage medium if necessary, so it does not impair the performance of the ext filesystem. However, journaling also causes far more write accesses to the underlying storage medium. For storage media with limited numbers of write cycles, such as flash storage, journaling therefore can drastically shorten the service life.
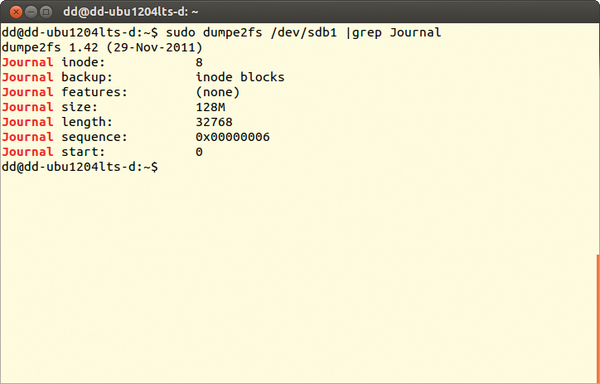 Figure 4: The dumpe2fs command displays information about the journal. The mode illustrated in this figure, inode blocks, corresponds to ordered mode.
Figure 4: The dumpe2fs command displays information about the journal. The mode illustrated in this figure, inode blocks, corresponds to ordered mode.
As mentioned previously, ext2 does not scale well if it is home to many thousands of files in subdirectories. When the system is asked to search for a given file, it needs to conduct a painstaking examination of all the entries in the directory inode.
To be better prepared for the future, the developers have already given the filesystem an HTree index structure. This tree-like structure allows ext3 to organize the contents of directories more effectively, making the search for files much faster.
The feature was originally developed for ext2, but it did not make it into the official source code at the time. Although it is enabled by default in ext4, ext3 still expects you to enable directory indexing manually. Also, ext3 lets you resize the filesystem while it is still mounted.
Additionally, you can define how the kernel behaves when it does not understand some of the filesystem metadata – for example, in case of damage. Depending on the configuration, the kernel can still mount the filesystem with restricted write access (writes are not recommended for reasons of data safety).
Similar to Windows filesystems, ext3 is prone to fragmentation when in constant use. Depending on how the free blocks are distributed across the filesystem, the system probably cannot always write contiguous data consecutively. The remedy for this problem is block preallocation, which ext3 uses to reserve the blocks before it actually needs them, which allows the filesystem to store the data as closely together as possible.
Incidentally, an online tool for defragmentation does not exist for ext3; however, several developers have released tools that at least optimize the distribution of the data somewhat. By adding a journal, you can convert an ext2 filesystem to an ext3 filesystem and vice versa.
The proximity to its predecessor is the biggest disadvantage of ext3: Because many structures resemble one another, ext3 initially lacked some features that competing filesystems already had. An ext3 filesystem with a block size of 4KB can accommodate a maximum file size of 2TB, and the filesystem can only grow to 16TB.
A few years after the publication of ext3, several companies and developers were still working on extensions and improvements (especially in terms of performance and stability). However, a lively debate developed on the kernel mailing list about whether further changes would really offer improvements to the fundamental problems or whether they would burden the existing users with even more disadvantages.
Finally, the developers agreed in 2006 to stop most of the work on ext3. Instead, they decided to copy the code of the filesystem to a new branch named ext4 and only add new features and make substantial changes there. More than two years later, ext4 made it into kernel 2.6.28, gradually becoming the standard for many distributions.
Ext4
Ext4 supports 64-bit processors, which makes it possible to create files with a size of 16TB for the first time, based on a block size of 4KB. The filesystem itself can grow to 1 exabyte (EB; approximately 1 million TB); this value is of a purely theoretical nature for most systems. In most cases, it is advisable to limit the filesystem size to around 16TB – and possibly to create several filesystems side by side.
Ext2 and ext3 store data in block bitmaps that represent the physical storage space. Under ext4, "extents" take over this feature in order to group contiguous blocks on the storage medium. A single extent on ext4 includes up to 128MB of contiguous space, and one inode contains up to four extents. If a file covers more than four extents, the filesystem indexes the remaining extents in a tree structure. Thanks to its use of extents, the ext filesystem can offer vastly improved performance for large files, as well as better defragmentation.
One feature painfully missed in ext3 was added by ext4: A new kernel function tells ext4 to reserve space for a file up front ( "pre-allocation"). Ext4 fills the area with zeros, then tries to guarantee that the storage space really is available and that it is as contiguous as possible.
Through further modifications, ext4 now supports more than 32,000 subdirectories per folder – theoretically almost an infinite number, because the HTree mechanism now always intervenes. If you need more than the standard 64,000 permissible subdirectories, select the dir_nlink feature.
The journal added in ext3 has seen a meaningful improvement: Checksums now prevent the potential risk of defective metadata, which could destroy the filesystem. The infamous filesystem check also runs significantly faster under ext4 because unused storage areas in the filesystem are marked as such. The software just skips unused areas, which speeds up the check significantly. Fans of very precise timestamps also appreciate the fact that ext4 supports timestamping with nanosecond accuracy. Ext4 now also has options for improving support for SSD storage media.
With the 4.1 kernel in mid-2015, experimental transparent encryption found its way into the ext4 filesystem [4]. As of kernel 4.4 this feature fulfills all the preconditions for future use. Incidentally, Google is the driving force behind ext4 encryption. Presumably, Google wants to offer better security features for Android and Chrome OS. If you are currently experimenting with a state-of-the-art kernel and newer userspace tools (e.g., tune2fs), check out some of the discussions online [5].
Ext4 provides backward compatibility with ext3 and ext2, which makes it possible to mount the predecessors as ext4 filesystems. However, you cannot mount an ext4 filesystem directly as an ext3 filesystem. To do so, you would first have to disable some features when creating the filesystem by adjusting the limits to reflect ext3's capabilities.
Ext4 introduced quotas in kernel 3.6 that allow admins to limit the storage space available to users and user groups. Project quotas were also introduced with the recently release of kernel version 4.5. Project quotas let you limit storage space either for directory hierarchies or for files scattered across multiple folders. The patches were already submitted at the end of 2014 and described in a post on the ext4 mailing list [6].
Future
Ext4 has been the default filesystem in many distributions over the past few years; after all, it is well suited for most purposes and is considered stable. Meanwhile, some distributors are moving to XFS (Red Hat) or Btrfs (openSUSE). Btrfs, in particular, is viewed as the leading contender to replace ext4 in the mid-term. (See the article on Btrfs elsewhere in this issue.) Btrfs includes many features that are unlikely to be added to ext4 in the foreseeable future, including filesystem snapshots, support for true online defragmentation, and copy-on-write operations.
Whether or not a fifth version of the ext filesystem will happen is currently uncertain. In the past, the next version of the filesystem was always launched as soon as enough changes accumulated to justify a next higher version, while the developers sought to keep the existing ext version as stable as possible.
A patch description was posted on the ext4 mailing list by Oracle Developer, Darrick J. Wong back in May 2014; his idea was at least to introduce a number of flags under the ext5 banner [7]. During the discussion, other developers plainly stated, however, that the suggested changes were not sufficient to found a new filesystem. More likely, the developers will continue actively working on ext4 for now. But in the mid-term, many users will probably change to Btrfs.
Infos
- Minix: http://www.minix3.org
- Unix filesystem: https://en.wikipedia.org/wiki/Unix_File_System
- E2compr: http://e2compr.sourceforge.net
- Ext4 encryption: https://lwn.net/Articles/639427/
- Blog post on ext4 encryption: http://blog.quarkslab.com/a-glimpse-of-ext4-filesystem-level-encryption.html
- Ext4 Quota patches: https://lwn.net/Articles/623835/
- Ext5 patch: https://www.marc.info/?l=linux-ext4&m=139898619610519&w=1
« Previous 1 2 3 4
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs
-
Juno Computers Launches Another Linux Laptop
If you're looking for a powerhouse laptop that runs Ubuntu, the Juno Computers Neptune 17 v6 should be on your radar.