An introduction to PostgreSQL
Not Your Dad's Database

© Lead Image © stockee, 123RF.com
PostgreSQL, an open source object-relational database management system known for its reliability and extensibility, offers a robust feature set. If you are new to PostgreSQL, we help you get started with some of its most useful features.
If you tracked the development of PostgreSQL in the '90s, you may remember it as a slow, resource hungry open source database later surpassed in popularity by the faster and easier to use MySQL. If that's the case, you might be surprised by PostgreSQL 16. While the name is the same, along with the similar syntax of familiar tools such as psql or pg_dump, the internal architecture has been vastly reworked. At the end of the day, it is basically a completely different database.
PostgreSQL is a mature, polished product that has been in development for almost 40 years. At the same time, it has developed at a rapid pace and offers many new, interesting features. In fact, it is practically impossible to describe all of these features in a single article, or even cover the most interesting features to the extent they deserve. In this article, I cover the most useful features for readers who are not currently using PostgreSQL.
The Elephant in the Room
In the past, an enterprise database management system (DBMS) was almost synonymous with Oracle, with IBM DB2 and Microsoft SQL Server (and at some point Sybase ASE and others) as competitors. While these DBMSs are still in use (mainly by large organizations who are by nature inert), there has been a move to migrate from proprietary to open source technologies. This emerging trend led Oracle to acquire MySQL from Sun Microsystems in 2010 (who acquired it from MySQL AB in 2008), which resulted in the MariaDB fork. This trend continues today, but this time PostgreSQL is the clear leader. PostgreSQL's stability, modern features, flexibility, and extensibility make it a universal DBMS that not only fits various use cases, but excels at them.
The MongoDB story illustrates PostgreSQL's performance capabilities. When the NoSQL movement gained in popularity, the new solutions like MongoDB were touted as superior to traditional SQL databases on many aspects, especially performance. In the end, PostgreSQL beat MongoDB with MongoDB's own benchmarks. While MongoDB has improved and fixed its many past flaws, more recent benchmark results still show PostgreSQL as a viable alternative to MongoDB in certain scenarios [1].
Legacy databases are unattractive to modern developers for many reasons. An open source database lets you immediately spin up a disposable instance and basically develop for it in no time. With closed solutions, even if you get a limited version such as Oracle XE, it's still quite complex compared to open source solutions (for an account of what Oracle calls "as easy as 'ABC'," see their blog [2] on installing Oracle XE in a Docker container to judge for yourself).
With PostgreSQL, on the other hand, you can put your relational DBMS (RDBMS) in a container and interact with it in just three steps. First, you need to get the most recent Docker image:
docker pull postgres
Then, run the server in the background:
docker run --name mypostgres -e POSTGRES_PASSWORD=mypassword-d postgres
Finally, connect to it with:
docker exec -it mypostgres psql -U postgres
That's it! Now you have a fully functional PostgreSQL client and server setup that you can use with some of the examples later in this article.
Eating the Database World
PostgreSQL fills a range of needs. In a blog post on Medium [3], the creator of Pigsty (an open source RDBMS alternative) [4] argues that PostgreSQL-based solutions are valid not just for online transaction processing (OLTP) but also for online analytical processing (OLAP) workloads thanks to ParadeDB [5] and for a SQLite-based option, see DuckDB [6]. PostgreSQL can do even more. If you need a graph database, you can use the Apache AGE PostgreSQL extension [7]. PostgreSQL allows you to connect to basically every modern database with Foreign Data Wrappers (FDWs) [8]. If you need a vector database, the pgvector extension works out of the box and has bindings for all popular languages. PostgreSQL offers a PostGIS extension if you need a geospatial database. The TimescaleDB extension [9] has you covered for time series databases. The list goes on.
You may be wondering how PostgreSQL performs and how it compares to other databases, as well as whether it will fit your use case. While you will need to figure out some of these answers for yourself, you can use the results of the ClickBench benchmark [10] as a guide. When you dig around, you will discover that the final result largely depends on whether PostgreSQL is fine-tuned for a particular use case or not. PostgreSQL is a universal and extremely flexible database, but you need to tune it for a particular load if you need to squeeze maximum performance out of it.
Another Brick in the WAL
Before turning to examples, it's important to understand a few key concepts related to how PostgreSQL works. Multiversion concurrency control (MVCC) is an important mechanism that provides concurrent access to the database by multiple clients without locking and without making it look inconsistent; MVCC is achieved by making multiple copies of the data [11]. Basically, MVCC enhances read performance by allowing transactions to view the database in a consistent state without locking data. This system has been refined over the years to reduce overhead and increase transaction throughput.
PostgreSQL's Write-Ahead Log (WAL) contains the records of changes. Because the changes are first written to WAL before being committed to disk, the log ensures data integrity. Think of it as an equivalent of the journal in the filesystem world (which is why, strictly speaking, PostgreSQL doesn't require a journaling filesystem). Because WAL contains the record of all changes in the database, it can be used to "replay" them (i.e., reconstruct the database), which can be used for backups and point-in-time recovery (PITR) where you can restore the database to any chosen point in time.
Shared memory contains the database and log cache, including the shared buffer whose main task is to minimize disk I/O operations, and the WAL buffer, which contains the content that has not yet been written to WAL. A checkpoint is a point in WAL where the data perfectly reflects the changes in WAL (think of the sync command for filesystems). You can enforce a checkpoint using the CHECKPOINT command. By default, a checkpoint happens every five minutes, but the setting can be controlled by the checkpoint_timeout parameter.
As for replication, physical replication operates at block device levels and replicates the physical data blocks. Logical replication replays the transaction in WAL on replicas.
You also need to understand the difference between database partitioning and sharding. Partitioning splits a large table into smaller, more manageable pieces, while still treating them as a single table. Sharding, on the other hand, distributes data across multiple database instances or servers and potentially across different physical locations. Sharding is suitable for very large databases where partitioning is not enough to achieve desired performance and scalability, but it comes with its own set of problems. Imagine you have a huge table containing the data of all citizens in a given country, ordered by birth date. With partitioning, you can split this huge table into many smaller ones by birth year. With sharding, you might put all citizens whose names start with an "A" in one database instance, those with "B" in another, and so on. Apart from the complexity in managing such a set up, an inherent problem is that, with time, sharded databases become unbalanced since you can't precisely predict how each instance will grow (e.g., instance "A" might grow more rapidly than instance "B").
PostgreSQL also supports parallel query processing (executing relevant queries on multiple cores/processors for enhanced performance), various types of indexing, foreign data wrappers, and many other useful features. I will describe some of these features in the examples that follow.
But How Do You Run It?
Infrastructure engineers are often more interested in how software is run than in how it is being used. In terms of performance, running PostgreSQL is quite simple: A single huge bare-metal instance will almost always offer superior performance for a lower price than an equivalent instance from a popular cloud provider. To give you a simple example, you can host a PostgreSQL instance on an AMD EPYC 7401P machine with 24 cores/48 threads, 512GB RAM, and 2x 960GB NVMe storage for under EUR300 per month. An equivalent AWS RDS instance provider would cost at least an order of magnitude more to just run the instance.
If a single bare-metal instance offers such good performance, then why isn't everybody running PostgreSQL this way? Today's databases are expected to run 24/7 with little or no downtime. A single bare-metal machine means that failures and even upgrades require downtime. Therefore, apart from a specific scenario when turning the database off for half an hour is not a problem, you will rarely see such a PostgreSQL setup.
A far more popular option involves at least two machines where one is known as the primary (formerly, "master") and the rest are replicas. The data from clients is written to the primary server only, and the replicas only get the copies of the data from the primary server. However, read operations also can be performed on replicas, reducing the load on the primary server. In most scenarios, a setup with a single primary and one or more replicas works reasonably well.
A more advanced setup involves multi-master (i.e., multi-primary) replication where more than one server can accept writes from clients, and these writes are then replicated between all servers. While multi-master replication offers availability and distributed access, it suffers in terms of consistency, performance, and integrity. Currently, this is where a lot of work is happening in PostgreSQL because this kind of set up is the most complex.
Modern Data Types
While PostgreSQL is praised for its features, they can also be a double-edged sword. Be aware that once you start using features that are not present in other databases, migrating to a different database will be more difficult. Moreover, intensive use of features like triggers and stored procedures is discouraged as they consume precious resources – and usually you want to reduce the load on your database machine, not increase it. That's why it's common to put a cache like Redis in front of the database to handle the most common queries to delay having to "scale vertically" (a euphemism for upgrading your hardware).
That said, as long as you are aware of the trade-offs, using all of PostgreSQL's possible features is not a problem. One especially appreciated class of features in PostgreSQL is its advanced data types. If you learned SQL, you are familiar with basic types such as INT, CHAR, DATE, and so on. Modern databases go beyond these types and provide users with more advanced and complex data types that suit common use cases. PostgreSQL is no exception, and it's worth knowing these data types whether you decide to use them or not.
hstore
The hstore data type is a key-value store within a single PostgreSQL value. It's useful for storing sets of key-value pairs within a single column, offering flexibility for semi-structured data. As an example, you can create a simple table:
CREATE TABLE products ( id serial PRIMARY KEY, attributes hstore );
and then insert the attributes as follows:
INSERT INTO products (attributes) VALUES ('color => "blue",size => "medium"');You can use hstore where you might have used MongoDB or another NoSQL database in the past: in scenarios where you have data whose structure is not clearly or fully defined, requiring it to be stored without a fixed table structure. In this scenario, you can modify attributes without modifying database schema. This is also useful if you are not sure which attributes will appear in the future and so on. In general, since the initial excitement over NoSQL waned, this kind of approach has been discouraged because it often leads to problems in the long run. However, for data that is primarily key-value in nature, such as configuration settings, profile attributes, or any scenario where the data structure is inherently a map or dictionary, hstore is an appropriate choice.
JSON and JSONB
JavaScript Object Notation (JSON) and PostgreSQL's JSONB, a special binary representation of JSON, are popular for storing and manipulating unstructured data. While JSON stores data in text format, JSONB stores it in a decomposed binary format, making it slower to insert but faster to query. For example, after creating a table with a JSON/JSONB data type:
CREATE TABLE users ( id serial PRIMARY KEY, profile JSONB );
You can query it using the following syntax:
INSERT INTO users (profile) VALUES ('{"name": "John", "age": 30,"interests": ["cycling", "hiking"]}');Because JSONB is quite popular, I'll discuss it in more detail in a practical example later in this article. For now suffice it to say that while JSON preserves the exact input format (such as whitespace and the order of keys) and is generally faster to store because of minimal processing, JSONB gives you several advantages in terms of efficient indexing and fast data access as well as a wider array of operators and functions for manipulating JSON data, making JSONB preferable when you need to frequently update or query JSON elements.
Arrays
Arrays in PostgreSQL are used to store multiple values in a single column. They can be particularly useful in various scenarios but come with their own set of considerations. For example, it might be tempting to simplify the model when you have a one-to-many relationship where the "many" side contains a small, fixed number of related items. Using an array in such a scenario avoids the need for additional join tables. Arrays can also improve efficiency when you frequently need to retrieve all related items simultaneously without performing a join operation. This can be especially beneficial when the array elements are often accessed together. Moreover, arrays can store not only simple types such as integers and strings but also composite types, allowing for the representation of complex and nested structures within a single column.
However, queries with arrays can quickly become complex and less intuitive. Also, updating individual elements of an array is more complex than updating values in a normalized table. While indexes can be created on array columns, they may not always be as effective as indexes on regular columns, especially for complex queries involving array elements. Therefore you should consider these trade-offs carefully.
A table with an array data type can be created as follows:
CREATE TABLE posts ( id serial PRIMARY KEY, tags text[] );
The values themselves are inserted using the following syntax:
INSERT INTO posts (tags) VALUES (ARRAY['science', 'technology','education']);
Spatial Data Types
When you deal with maps, suddenly a whole class of questions becomes relevant, starting from the simple (e.g., "What is the distance between these two places?") to the more complex (e.g., "What points of interest can be found in a given area?"). PostgreSQL contains a collection of spatial data types to handle these issues. While this topic deserves a separate article, I'll cover the basics here.
To store spatial data, you must create tables with spatial columns, for example:
CREATE TABLE spatial_data ( id SERIAL PRIMARY KEY, location GEOMETRY(POINT, 4326) );
This SQL statement creates a table with a POINT type geometry column, specifying spatial reference identifier (SRID) 4326, commonly used for geographic coordinate systems. To insert a point into the location column using the ST_GeomFromText function, which converts text to a spatial data type, type:
INSERT INTO spatial_data (location) VALUES (ST_GeomFromText('POINT(-71.060316 48.432044)', 4326));Apart from the ST_GeomFromText, PostgreSQL offers other functions such as ST_Area to calculate the area of a polygon and ST_Distance to compute the shortest distance between two geometries. PostgreSQL also supports many useful geospatial data types such as MULTIPOLYGON, which can represent disjointed territories of a single entity, like islands that are part of a country along with a mainland.
DIY Data Types
When none of the built-in data types are enough, you can easily build your own, defining a so-called composite data type. For example, if you define a new type that describes an address:
CREATE TYPE address_type AS ( street VARCHAR(255), city VARCHAR(100), state CHAR(2), zip_code VARCHAR(10) );
You can later use it in a table:
CREATE TABLE library_branch ( branch_id SERIAL PRIMARY KEY, branch_name VARCHAR(255) NOT NULL, location address_type );
Inserting is equally simple:
INSERT INTO library_branch (branch_name, location)
VALUES ('Downtown Branch', ROW('123 Main St', 'Anytown', 'NY','12345'));When querying data, you use dot notation:
SELECT branch_name, location.city AS city FROM library_branch;
Internally, PostgreSQL treats these types as if they were rows in a table, with the fields of the composite type corresponding to columns in a table. Composite types can be used as column data types in tables, as return types for functions, or as arguments for functions. This provides significant flexibility in passing complex structured data. While you cannot directly create indexes or enforce constraints on individual fields within a composite type when used as a column, you can achieve similar functionality by utilizing functional indexes or constraints on the table where the composite type is used.
Unfortunately, using composite types can introduce overhead compared to using simple types, especially if you frequently need to access or manipulate individual fields within the composite type. Also, while using composite types can make your schema more organized and semantically clear, they can also add complexity, particularly when it comes to writing queries and managing the database schema.
JSONB in a Sample App
Leaving academic discussion aside, I'll move to a practical example. As a web app developer, you may want to know if you can use PostgreSQL to provide persistence for a web app written in JavaScript. You also may be wondering how difficult it is to manage the database connection and how to deploy it. Finally, you may want to know if you can store data in JSON and query it natively. I'll provide a simple example answering some of these questions.
Traditionally, the equivalent of a "Hello, world!" application in front-end development is a simple task management app. Because this is an article on PostgreSQL, I'll concentrate on how JSON is sent by the back end.
Listing 1 contains a barebones Flask app with SQLAlchemy database management, whereas Listings 2 and 3 include the related HTML and vanilla JavaScript files (remember to put these files in the scripts subfolder). The HTML and JavaScript files communicate with the Flask back end listening on localhost on port 5000 using the tasks/ endpoint.
Listing 1
A Sample Flask App
01 from flask import Flask, request, jsonify, send_from_directory
02 from flask_sqlalchemy import SQLAlchemy
03 from flask_cors import CORS
04 from sqlalchemy.dialects.postgresql import JSONB
05
06 app = Flask(__name__, static_url_path='', static_folder='static')
07 CORS(app) # Initialize CORS with default parameters
08
09 app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://taskuser:taskpassword@postgres/taskdb'
10 app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
11 db = SQLAlchemy(app)
12
13 class Task(db.Model):
14 id = db.Column(db.Integer, primary_key=True)
15 name = db.Column(JSONB, nullable=False) # Change to JSONB
16 parent_id = db.Column(db.Integer, db.ForeignKey('task.id'), nullable=True)
17 subtasks = db.relationship('Task', backref=db.backref('parent', remote_side=[id]), lazy=True)
18
19 with app.app_context():
20 db.create_all()
21
22 @app.route('/tasks', methods=['POST'])
23 def create_task():
24 data = request.get_json()
25 task = Task(name=data['name'], parent_id=data.get('parent_id'))
26 db.session.add(task)
27 db.session.commit()
28 return jsonify({'id': task.id, 'name': task.name, 'parent_id': task.parent_id}), 201
29
30 @app.route('/tasks', methods=['GET'])
31 def get_tasks():
32 tasks = Task.query.all()
33 tasks_list = []
34 for task in tasks:
35 tasks_list.append({
36 'id': task.id,
37 'name': task.name,
38 'parent_id': task.parent_id
39 })
40 return jsonify(tasks_list)
41
42 @app.route('/tasks/<int:task_id>', methods=['GET'])
43 def get_task_with_subtasks(task_id):
44 task = Task.query.get(task_id)
45 if not task:
46 return jsonify({'message': 'Task not found'}), 404
47
48 def serialize_task(task):
49 return {
50 'id': task.id,
51 'name': task.name,
52 'subtasks': [serialize_task(subtask) for subtask in task.subtasks]
53 }
54
55 return jsonify(serialize_task(task))
56
57 @app.route('/')
58 def index():
59 return send_from_directory('static', 'index.html')
60
61 if __name__ == '__main__':
62 app.run(debug=True)
Listing 2
script/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Task Manager</title>
</head>
<body>
<h1>Task Manager</h1>
<div>
<input type="text" id="taskName" placeholder="Task Name">
<input type="number" id="parentTaskId" placeholder="Parent Task ID (Optional)">
<button onclick="createTask()">Create Task</button>
</div>
<div id="tasks"></div>
<script src="script.js"></script>
</body>
</html>
Listing 3
scripts/script.js
01 function createTask() {
02 const name = { text: document.getElementById('taskName').value };
03 const parent_id = document.getElementById('parentTaskId').value;
04
05 fetch('/tasks', {
06 method: 'POST',
07 headers: {
08 'Content-Type': 'application/json',
09 },
10 body: JSON.stringify({ name, parent_id: parent_id || null }),
11 })
12 .then(response => response.json())
13 .then(data => {
14 alert('Task Created: ' + data.name.text);
15 loadTasks();
16 })
17 .catch((error) => {
18 console.error('Error:', error);
19 });
20 }
21
22 function loadTasks() {
23 fetch('/tasks')
24 .then(response => response.json())
25 .then(tasks => {
26 const tasksElement = document.getElementById('tasks');
27 tasks Element.innerHTML = '';
28 tasks.forEach(task => {
29 const taskElement = document.createElement('div');
30 taskElement.textContent = `ID: ${task.id}, Name: ${task.name.text}, Parent ID: ${task.parent_id || 'None'}`;
31 tasksElement.appendChild(taskElement);
32 });
33 });
34 }
35
36 document.addEventListener('DOMContentLoaded', function() {
37 loadTasks();
38 });
In the Flask app in Listing 1, the functions used to create and get tasks return JSON responses. When looking at the code, you may wonder exactly where the tasks are being saved in the PostgreSQL database. In lines 23-27, you see that the create_task() function calls db.session.add() and db.session.commit(). When the database transaction is committed successfully, the task is permanently stored in the PostgreSQL database as defined in the SQLAlchemy configuration. Now, when you type http://localhost:5000 in your browser, you should see the Flask app's main screen where you can add tasks and subtasks (Figure 1) and see the corresponding JSON structure (Figure 2).
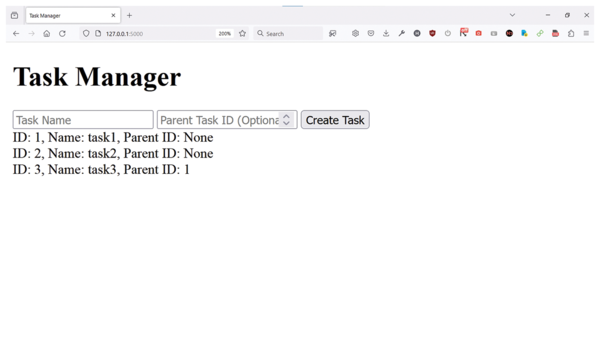 Figure 1: The Flask app task manager.
Figure 1: The Flask app task manager.
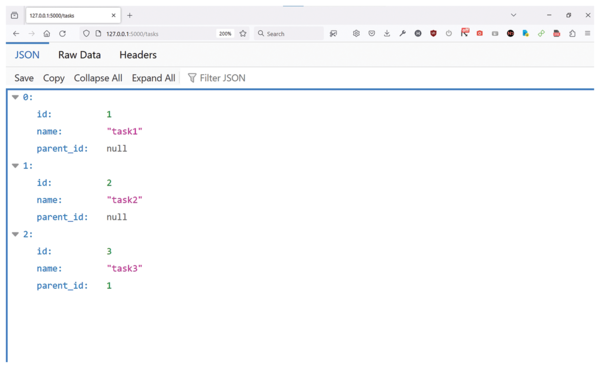 Figure 2: The corresponding JSON structure for the Flask app.
Figure 2: The corresponding JSON structure for the Flask app.
To run the example Flask app, you will need a Dockerfile (Listing 4), a requirements.txt file for Python modules used (Listing 5), and, finally, the docker-compose.yml file with the instructions on how to run the Flask app and PostgreSQL (Listing 6). Listing 6 defines two Docker services (postgres and flaskapp) and one Docker volume (postgress_data) mounted at /var/lib/postgresql/data. Note that I have defined the connection parameters, including the password, directly in the files – in a real use case it should be stored in an appropriate secrets store such as Vault.
Listing 4
A Sample Dockerfile for the Flask App
FROM python:3.11-slim WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . CMD ["flask", "run", "--host=0.0.0.0"]
Listing 5
requirements.txt
flask flask_sqlalchemy flask-cors psycopg2-binary
Listing 6
docker-compose.yml
01 services: 02 postgres: 03 image: postgres:latest 04 environment: 05 POSTGRES_USER: taskuser 06 POSTGRES_PASSWORD: task password 07 POSTGRES_DB: taskdb 08 ports: 09 - "5432:5432" 10 volumes: 11 - postgres_data:/var/lib/postgresql/data 12 13 flask app: 14 build: . 15 ports: 16 - "5000:5000" 17 volumes: 18 - .:/app 19 environment: 20 FLASK_APP: app.py 21 FLASK_RUN_HOST: 0.0.0.0 22 depends_on: 23 - postgres 24 command: ["flask", "run", "--host=0.0.0.0"] 25 26 volumes: 27 postgres_data:
This example is interesting because the task data, although simple, is not stored as varchar but as JSONB. You can quickly check it by connecting to the local PostgreSQL instance using the pl sql tool and the URI defined in the Flask app:
psql "postgresql://taskuser:taskpassword@localhost/taskdb"
(Note: Typing the password as shown above is insecure because it can be revealed in your shell history.) After connecting to the database, you can describe the table task (\d task) and query it: Notice that the internal representation is JSONB, and the data displayed by the SELECT statement is JSON (Figure 3).
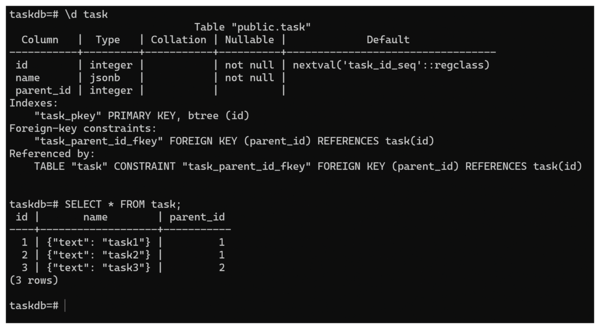 Figure 3: The table's internal structure is in JSONB, but the data displayed by SELECT is in JSON.
Figure 3: The table's internal structure is in JSONB, but the data displayed by SELECT is in JSON.
As you can see, creating a simple Flask app using PostgreSQL as an RDBMS with JSON/JSONB as the data type is quite easy. Even though a lot of usual chores related to handling database connections are outsourced to SQLAlchemy to make the code cleaner and shorter, I could have done it manually with relatively few changes. Although this example is by necessity oversimplified, it contains a fully working web app with the data passed between the front end and the database using the Flask back end.
What About Kubernetes?
As PostgreSQL has matured over the years, the support for running it on a Kubernetes cluster has also improved. Generally speaking, when using Kubernetes, you have two distinct options as far as persistent data is concerned: You can either use databases inside the cluster or outside of it. Both have different trade-offs, with running outside the cluster being the traditional and generally more predominant option. However, in recent years, more and more companies have begun using operators to run their databases inside the cluster and are very happy with it. In fact, some users think running PostgreSQL in Kubernetes is now better than running PostgreSQL on virtual machines – thanks to the hard work of many people and projects such as CloudNativePG.
CloudNativePG is a Kubernetes operator using primary/standby architecture and streaming replication. When the primary dies, the operator chooses the new one from among the read replicas. It also readjusts the number of replicas together with all related resources such as persistent volumes (PVs) and persistent volume claims (PVCs), scaling them up and down depending on your requirements. It also performs several other tasks making sure applications connecting to the cluster see it as one coherent and performant database in spite of its content being distributed over several machines. For an excellent case analysis of this type of setup, see Chris Milsted and Gabriele Bartolini's presentation on running PostgreSQL in a Kubernetes cluster [12].
Foreign Data Wrappers
While some might claim that PostgreSQL is the "most admired and desired database" in the world [13], it is definitely not the only one. Sometimes you will need to grab data from another database. The good news is that you can do this without leaving PostgreSQL. PostgreSQL's Foreign Data Wrappers (FDWs) allow you to access data from external sources as if the data were residing in a local table. This is facilitated through the SQL Management of External Data (SQL/MED) extension. The server you connect to doesn't even need to run a different database engine – it could be just another PostgreSQL instance.
First, you need to ensure that the required FDW extension is installed. For example, if you're connecting to a MySQL database, you might need the mysql_fdw extension [14]. Next, define a foreign server, which represents the external data source. This includes the type of server (e.g., MySQL, another PostgreSQL server, etc.) and connection details. To connect to a different PostgreSQL instance, you would use the following:
CREATE SERVER my_foreign_server FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'foreignhost', port '5432', dbname 'foreign_db');
Next, you need to create a user mapping to define which local user corresponds to which user on the foreign server; credentials can be included here:
CREATE USER MAPPING FOR local_user SERVER my_foreign_server OPTIONS (user 'foreign_user', password 'foreign_password');
At this point, you can define a foreign table that mirrors the structure of the table on the foreign server. This definition includes column names and types:
CREATE FOREIGN TABLE foreign_table ( id integer, data text ) SERVER my_foreign_server OPTIONS (schema_name 'public', table_name 'foreign_table');
That's it! A simple
SELECT * FROM foreign_table;
will work just like it would with a normal table on the local instance.
Be aware that querying foreign tables can be slower than local tables. Optimization strategies such as appropriate indexing on the foreign server, wise use of predicates in queries, and materialized views can help to mitigate this – at least to a certain extent. Moreover, FDW connections need to be maintained. Obviously schema changes on the foreign server require corresponding changes on the PostgreSQL side. Otherwise, your queries won't work as expected. For most scenarios, it is better to treat FDW as a quick, temporary workaround for a specific problem where a proper solution would be too expensive.
Conclusion
Due to space constraints, I described only a very limited set of features supported by PostgreSQL, leaving out such important areas as indexing (aside from default B-tree indexing, PostgreSQL supports many other options, such as GiST, GIN, or BRIN, that work better for particular scenarios), extensions, languages options for functions, stored procedures, and many others. However, I hope that even this little overview helps you to understand why PostgreSQL is so valued by users worldwide.
Whether you are a software or infrastructure engineer, you need to know at least one database well, and PostgreSQL is an excellent candidate. It can be as simple or as complex as desired: You can start small with little projects like the one described in this article and grow to complex setups in terms of the database itself as well as the supporting infrastructure. PostgreSQL is truly unique in its flexibility. You will not regret learning it.
This article was made possible by support from Percona LLC through Linux New Media's Topic Subsidy Program (https://www.linuxnewmedia.com/Topic_Subsidy).
Infos
- "Can PostgreSQL with its JSONB column type replace MongoDB?" by Yuriy Ivon, Medium, August 2, 2023, https://medium.com/@yurexus/can-postgresql-with-its-jsonb-column-type-replace-mongodb-30dc7feffaf3
- "Deliver Oracle Database 18c Express Edition in Containers" by Adrian Png, September 12, 2019, https://blogs.oracle.com/connect/post/deliver-oracle-database-18c-express-edition-in-containers
- "Postgres is eating the database world" by Vongg, Medium, March 14, 2024, https://medium.com/@fengruohang/postgres-is-eating-the-database-world-157c204dcfc4
- Pigsty: https://github.com/Vonng/pigsty/
- ParadeDB: https://www.paradedb.com/
- DuckDB: https://duckdb.org/
- Apache AGE: https://age.apache.org/
- FDWs: https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- TimescaleDB: https://github.com/timescale/timescaledb
- ClickBench: https://benchmark.clickhouse.com/
- MVCC: https://en.wikipedia.org/wiki/Multiversion_concurrency_control
- "Data on Kubernetes, Deploying and Running PostgreSQL and Patterns for Databases in a Kubernetes Cluster" by Chris Milsted and Gabriele Bartolini, https://www.youtube.com/watch?v=99uSJXkKpeI
- "Postgres is the Undisputed Most Admired and Desired Database in Stack Overflow's 2023 Developer Survey" by Marc Linster, June 22, 2023, https://www.enterprisedb.com/blog/postgres-most-admired-database-in-stack-overflow-2023
- mysql_fdw for PostgreSQL: https://github.com/EnterpriseDB/mysql_fdw