
Programming for the Amazon EC2 cloud
Lofty Code

© Iakov Kalinin, Fotolia
We show you some techniques for harnessing the benefits of cloud technology.
Everyone is talking about the promise of cloud computing, but when it comes to implementation, some of the early adopters have simply deployed cloud services by copying older methods used in conventional environments. In fact, the cloud can do much more for you. Running sites on EC2 is easy, but really making use of the scalability and flexibility of cloud computing requires a new approach (Figure 1). In this article, I describe some techniques for building the benefits of cloud computing into your infrastructure. Although I use examples based on the Ruby language and Amazon's EC2 cloud environment, these concepts also apply to other languages and cloud vendors.
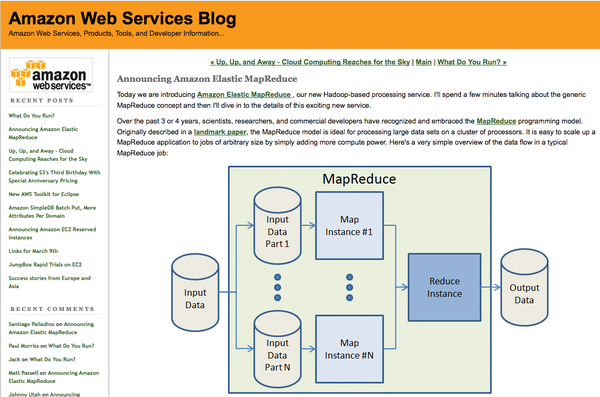 Figure 1: Amazon recently added MapReduce to their list of services. As if cache, computing, and queues aren't enough, now you can run huge, distributed tasks.
Figure 1: Amazon recently added MapReduce to their list of services. As if cache, computing, and queues aren't enough, now you can run huge, distributed tasks.
Keep It Static
In the cloud, you don't need everything to go through your server (even if it is virtual). You don't need a virtual server for serving files, managing queues, and storing shared data. Dedicated services can perform these tasks, and using them will help you get your applications working better in the cloud.
Online Storage
In this first example, you use an online storage service to host your static files. Because it takes an unnecessary load off of your web servers, online storage is good practice for any site operating within the cloud paradigm. In the case of the Amazon environment, the S3 service (Simple Storage Service) will play host to your static files.
Let's suppose you have a simple Ruby application, such as a blog or wiki. When your users upload a file, it is usually stored on the filesystem; instead, you could push the file to S3 directly.
To do this in Ruby, start by installing the library:
sudo gem install aws-s3
Then create a simple script like the one shown in Listing 1.
Listing 1
Working with S3
Pushing a file to S3 and making it public takes just one line:
AWS::S3::S3Object.store(
'example.jpg',
open('example.jpg'),
'my-public-bucket',
:access => :public_read
)Of course, the URL will be different, so you must change the link in the blog post. The preceding example creates the URL:
http://s3.amazonaws.com/my-public-bucket/example.jpg
Pushing all your static files to S3 is relatively simple – you can think of S3 as a huge static file server. More interesting is SQS, which really takes you into solving problems in a scalable way.
SQS
SQS is a queue server, which hosts a queue of data that applications can add to and remove from. This apparently trivial task makes scaling big tasks easy. Instead of needing to run all your tasks in one place and keeping everything coordinated, you can push a list of tasks onto the queue, fire up a dozen servers, and watch them work through the queue.
For example, imagine that you need to prepare a large number of personalized recommendations for customers. In a normal LAMP environment, you would need to work through a list of user records, create a set of recommendations, and store the information in a second database table. With SQS, you can split the process. In other words, you can "decouple" the process by pushing the information onto the queue in the first script and then processing the data in the queue in the second script.
Working in Rails, you can install the SQS bindings for Ruby and push a model onto the queue using the to_xml method:
q = SQS.get_queue "work-out-some-recommendations" q.send_message myobject.to_xml
This code means that an XML entry in the work-out-some-recommendations queue will look something like the following:
<myobject> <user>Mr. Smith</user> <favorite_products> <product>2412</product> <product>9374</product> <product>1029</product> </favorite_products> </myobject>
Next, you need to get this XML entry out of the queue and do something with it:
q = SQS.get_queue "work-out-some-recommendations" queue_item = q.receive_message work_object = MyObject.new() work_object.from_xml queue_item.body
Work_object is just the same as myobject was above, but with an important difference: You don't need to connect to the original database, so you won't have any issues with the number of connections and the speed of the database server.
You're free to use the XML to build a message, which you can then push to S3 for later use by any other part of the application (Listing 2). Notice that this message isn't public. Because you are only going to use them internally, there is no need to expose these snippets.
Listing 2
Building a Message
When building your web pages, you can save a few CPU cycles by pulling the welcome message from S3 rather than connecting to any other server:
cached_snippet = AWS::S3::S3Object.find 'Welcome-dan@example.com', 'welcome-messages'
All I have really done here is caching. Using SQS and S3 provides a completely scalable way of caching that doesn't affect the performance of your site at all.
Interoperability
The providers of cloud computing services – Amazon [1], GoGrid [2], Rackspace [3], and Google [4] – currently offer slightly different suites of services. Interoperability is a big issue among those in the cloud ecosystem, because tying your app to a single provider could hurt in the long run; if your scalable app works only on EC2, how do you migrate if (or when) one of the other vendors offers a lower cost?
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Canonical Releases Ubuntu 24.04
After a brief pause because of the XZ vulnerability, Ubuntu 24.04 is now available for install.
-
Linux Servers Targeted by Akira Ransomware
A group of bad actors who have already extorted $42 million have their sights set on the Linux platform.
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.