
In-Memory DBMS
Main memory database systems
ByThanks to powerful hardware, in-memory databases run without accessing mass memory devices, which means they handle transactions and evaluations at high speed, introducing a paradigm shift in the database market.

In-memory database management systems (DBMSs), such as TimesTen by Oracle and solidDB by IBM, have been around for some time. These database systems keep the entire data set in RAM, thus removing the need to swap pages between the main memory buffer and the hard disk, as is the case with legacy DBMSs. However, in-memory database systems – until now – have tended to be niche products for special applications.
Masses of Memory
Progress in hardware has changed all that. Today’s servers have upward of 1TB of RAM and multiple cores, and new algorithms and data structures for RAM-efficient data processing are now in use along with cache-efficient data record structures, such as PAX or column stores, compression, and cache-efficient index structures. In-memory DBMSs will likely become even more important if you consider the following: Today’s enterprises can buy relatively cheap servers with a RAM capacity of more than 1TB for under US$ 50,000. These servers have multiple-core processors capable of executing many threads in parallel. The capacity is sufficient to store the transactional data of even the largest corporation – we’re not talking about multimedia data here, but about data for mission-critical transactions.
For example, look at the ordering data of a trader such as Amazon. In 2011, Amazon generated a turnover of some US$ 48 billion. At an average product price of US$ 25, the company is thus storing around 2 billion order items, each of which can typically be represented by less than 100 bytes of data. This gives a storage volume of around 200GB – which will easily fit into 1TB of RAM. This calculation doesn’t take other relations (customers, products, etc.) into consideration, but neither does it consider compression options. Alternatively, a large enterprise could set up a distributed, partitioned database on a cluster.
Start-Up Topics
The technological advances in server hardware have led to the foundation of many start-ups in the field of in-memory DBMS: VoltDB, Clustrix, Akiban, dbShards, NimbusDB, ScaleDB, Lightwolf, and ElectronDB, to name just a few better known examples. Also large corporations such as SAP (NewDB/Hana) and IBM (ISAO/Blink) are investing in this direction.
In many cases, these new developments rely on open source database systems, such as MySQL or PostgreSQL as the basis for their main memory optimizations. Besides the commercial Enterprise Editions, vendors typically also offer a free version that has less functionality. VoltDB, for example, is available as a GPLv3-licensed Community Version.The previous in-memory database systems have been designed for specific use cases: either online transaction processing (OLTP), efficient transaction processing, or online analytical processing (OLAP). However, convincing arguments, like those put forward by SAP founder Hasso Plattner [1], posit that this division doesn’t support the user requirements sufficiently in terms of real-time business intelligence.
Shooting Down Paradigms
Today’s typical database architecture mainly envisages managing transactional data on an OLTP database system that always maintains the latest status. From there, an extract transform load (ETL) process transfers the data into an OLAP system (data warehouse). This operation can only occur periodically (e.g., once a night) for reasons of load. Previous systems have been unable, for performance reasons, to execute OLAP queries directly against the data on the OLTP system.
This process is changing because of the up-and-coming in-memory DBMSs, referred to as hybrid OLTP and OLAP databases. They combine the best properties of both worlds, as you can see from Figure 1.
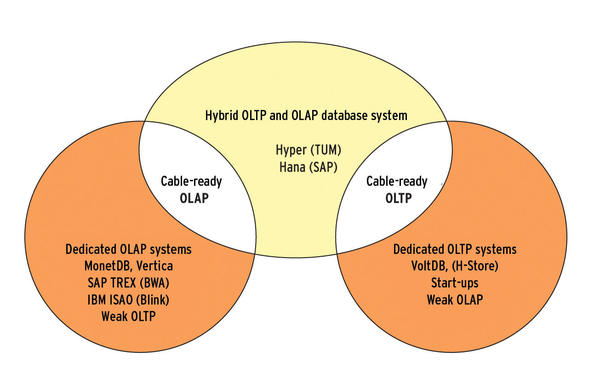 Figure 1: In-memory DBMS overview, primarily optimized for OLAP (left) or OLTP (right). Very few offer the best of both worlds (center).
Figure 1: In-memory DBMS overview, primarily optimized for OLAP (left) or OLTP (right). Very few offer the best of both worlds (center).
Their transaction throughput is just as fast as that of a dedicated OLTP database (e.g., VoltDB), and in terms of query processing, they are capable of holding sway with dedicated OLAP engines, such as the column store monet-DB, Vertica, Vectorwise, or IBM ISAO/Blink system.
Hana, developed by SAP, and HyPer, from the Technical University of Munich, are probably the best known representatives of hybrid systems designed for operational business intelligence. HyPer is a state-of-the-art in-memory DBMS that leverages hardware-supported virtual memory management on the operating system side for data management and synchronization between OLTP transactions and OLAP queries.
“In-core” data management maps the relational data directly to the virtual address space of the OLTP process, without any indirection via a DBMS-controlled buffer and page management system. It can create transaction-consistent database snapshots by fork()ing a new OLAP process. The copy-on-write mechanism of the operating system and processor keeps the snapshot consistent by replicating pages with changing data objects.
This snapshot method is equivalent to the shadow page concept developed by Lorie in 1977 for IBM [2] – the difference being that virtual memory snapshots suffer from none of the drawbacks of the period: Memory fragmentation is not an issue in RAM, and what used to be expensive software controlled management of the shadow copies is now highly efficient in the HyPer approach because of built-in processor support.
Additionally, virtual memory management allows you to keep an arbitrary number of (time-staggered) shadow copies. This makes it possible to implement a database system with HyPer that combines the benefits of OLTP and OLAP databases. HyPer’s transaction throughput is comparable to or better than that of the dedicated OLTP systems (e.g., VoltDB), and in terms of OLAP query processing, HyPer is comparable to dedicated column stores like MonetDB or Vectorwise.
Info
[1] Plattner, Hasso, and Alexander Zeier. In-Memory Data Management: An Inflection Point for Enterprise Applications. Springer-Verlag, 2011
[2] Lorie, R.A. Physical integrity in a large segmented database. TODS 1977;2(1):91-104
Authors
Alfons Kemper is the Chair of Database Systems at the Technical University of Munich. His research interests include Internet data processing, in-memory DBMSs, distributed database systems, and query optimization.
Thomas Neumann is a professor at the Technical University of Munich. His research involves database performance optimization – especially query optimization. He developed the HyPer system for relational in-memory databases, as well as RDF-3X for RDF databases.
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Container-Based Fedora Hummingbird Designed for Agent-First Builders
Fedora Hummingbird brings the same approach to the host OS as it does to containers to level up security.
-
Linux kernel Developers Considering a Kill Switch
With the rise of Linux vulnerabilities, the kernel developers are now considering adding a component that could help temporarily mitigate against them… in the form of a kill switch.
-
Fedora 44 Now Gaming Ready
The latest version of Fedora has been released with gaming support.
-
Manjaro 26.1 Preview Unveils New Features
The latest Manjaro 26.1 preview has been released with new desktop versions, a new kernel, and more.
-
Microsoft Issues Warning About Linux Vulnerability
The company behind Windows has released information about a flaw that affects millions of Linux systems.
-
Is AI Coming to Your Ubuntu Desktop?
According to the VP of Engineering at Canonical, AI could soon be added to the Ubuntu desktop distribution.
-
Framework Laptop 13 Pro Competes with the Best
Framework has released what might be considered the MacBook of Linux devices.
-
The Latest CachyOS Features Supercharged Kernel
The latest release of CachyOS brings with it an enhanced version of the latest Linux kernel.
-
Kernel 7.0 Is a Bit More Rusty
Linux kernel 7.0 has been released for general availability, with Rust finally getting its due.
-
France Says "Au Revoir" to Microsoft
In a move that should surprise no one, France announced plans to reduce its reliance on US technology, and Microsoft Windows is the first to get the boot.