
Bulk renaming files with the rename command
Names Have Been Changed

© Photo by CHUTTERSNAP on Unsplash
The rename command is a powerful means to simultaneously rename or even move multiple files following a given pattern.
Users often have to rename a collection of related files according to a specific pattern. You might have logfiles with dates and times in the file name, but the dates are not written in your preferred format (20230315 instead of 15-03-2023). Perhaps you have a collection of digital photos from your camera, or maybe you are working with files created on an old Microsoft Windows or MS-DOS system that are all uppercase, and you want to give them more readable file names.
Changing the names of a few files by hand may be manageable, but changing more than a dozen files quickly becomes not only tedious but error-prone. Linux does have some tools that will rename files in bulk. Most notably, the Thunar file manager [1] has a very flexible Bulk Rename tool (Figure 1), with several powerful built-in pattern-matching criteria from which to choose, making the tool sufficient for most use cases.
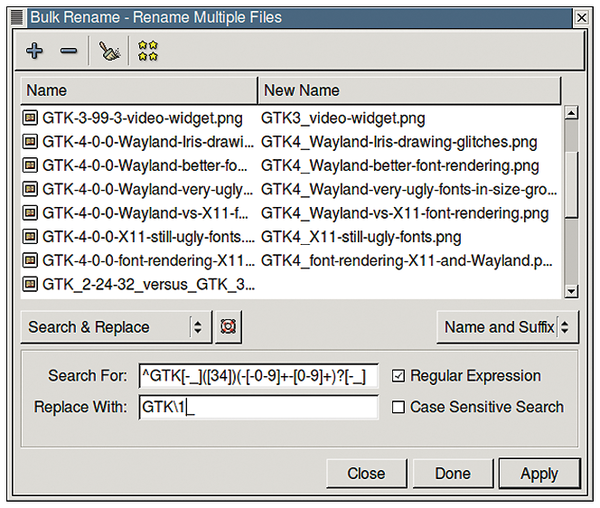 Figure 1: The Bulk Rename tool features many advanced capabilities, but it may not be as efficient as a command-line tool in the hands of an experienced user.
Figure 1: The Bulk Rename tool features many advanced capabilities, but it may not be as efficient as a command-line tool in the hands of an experienced user.
Once you get used to the command line, renaming files with a text-based command is usually faster than using a graphical tool. Plus, Thunar's Bulk Rename tool, although powerful, is still limited in its flexibility. For example, while Bulk Rename can rename files, it usually cannot move files from one directory or group of directories to another.
This article takes a deep look at the rename command [2], a very powerful command-line tool written in Perl that you can use for bulk renaming and a whole lot more.
Getting Started
If you don't have rename on your system, you can install it on Debian, Ubuntu, and derivatives with the following command:
sudo apt install rename
The rename command has the following syntax:
rename [options] [expression] [files]
The files are one or more files to rename. As with other command-line tools, standard shell wildcards such as *.png or file[0-9] are permitted.
The expression consists of commands to match and change parts of the file names; the results of applying the expression to each file name are used to give the file a new name. Usually, you will specify only one command – the s/// command for searching (or, less often, the y/// command for exchanging or transliterating individual letters) – to change uppercase file names to lowercase.
However, the expression can actually be almost any valid Perl code that operates on strings. If you are interested in Perl expressions, see the official Perl documentation [3]. However, it is unlikely that you'll need more than the s/// and y/// commands for changing file names.
In addition, rename accepts one or more options (see Table 1 for the most useful options).
Table 1
Useful rename Options
| Option | Meaning |
|---|---|
| -n, --nono |
Does not rename or move any files. This option is most useful when combined with the -v option, to show what would be done without actually renaming any files. |
| -v, --verbose |
Prints each file's name, both before the expression is applied and after. This is useful to test the effects of the rename expression, especially when combined with the -n option. |
| -f, --force |
Proceeds with renaming the files, even files which, once renamed, would have names that clash with existing files. Normally, rename will not rename a file if a file already exists with that name. When used, the renamed file will overwrite any existing file with the same name. Use with caution. |
| --path, --fullpath |
Operates on the file's full pathname, not just the file name itself. For example, replacing all instances of the word JPG with JPEG on the file at Pictures/JPGs/1.JPG not only renames the file to 1.JPEG, but moves the file to Pictures/JPEGs/1.JPEG as well. This is rename's default behavior, so you should rarely need to specify this option explicitly. |
| -d, --filename, --nopath, --nofullpath |
Operates only on the name of the file itself, rather than the full pathname of the file. Replacing all instances of the word JPG with JPEG in the file at Pictures/JPGs/1.JPG will rename the file to Pictures/JPGs/1.JPEG. |
| -u, --unicode |
Normally, rename expects file names to be plain ASCII text. This option specifies Unicode format. An optional parameter specifies the exact character encoding for the file names. |
A Basic Example
For my first example, I have some HTML files of Wikipedia articles that I downloaded using my web browser (see Listing 1). My web browser conveniently named each web page after the page's title. However, each page's title (and thus file name) ends with a hyphen followed by the word "Wikipedia," which is redundant and unnecessarily lengthens the name of each file.
Listing 1
HTML File Names with Redundant Text
$ ls -N IEEE 754 - Wikipedia.html Iron oxide - Wikipedia.html Key Code Qualifier - Wikipedia.html Wikipedia - Wikipedia.html
To remove the trailing "Wikipedia" and the hyphen, I will search for files whose names end with a space, a hyphen, another space, the word "Wikipedia," and the string ".html" and replace all that with just the string ".html" using the following command:
rename 's/ - Wikipedia\.html$/.html/' *.html
The s/// command searches for the part of the file name matching a pattern (enclosed between the first two slash characters as shown in annotation 1 in Figure 2) and replaces the matched text with some other text (enclosed between the second and third slashes, annotation 2 in Figure 2). Listing 2 shows the results of running this s/// command.
Listing 2
New File Names After Running rename
01 $ rename 's/ - Wikipedia\.html$/.html/' *.html 02 $ ls -N 03 IEEE 754.html 04 Iron oxide.html 05 Key Code Qualifier.html 06 Wikipedia.html
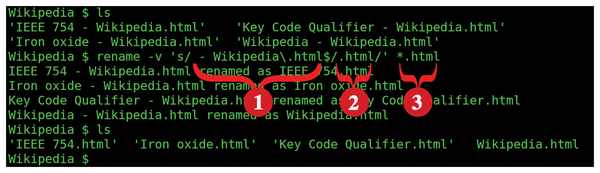 Figure 2: A simple but typical rename command: The command searches for the search text (1) and replaces any occurrence of it with the replacement text (2) in each of the supplied file names (3).
Figure 2: A simple but typical rename command: The command searches for the search text (1) and replaces any occurrence of it with the replacement text (2) in each of the supplied file names (3).
Note the backslash (\) character preceding the dot character (.) in the search term (line 1 of Listing 2). The search expression uses regular expression syntax [4], and the dot character has a special meaning in regular expressions. When not preceded by a backslash (known as an escape), a dot character will match not only a single dot character in the file name, but will match any kind of character. If I had not escaped the dot and had instead searched for simply - Wikipedia.html with a leading space, the search expression would have matched files (again all with leading spaces) named - Wikipedia.html, - Wikipediazhtml, - Wikipedia!html, and so on.
In practice, the set of files I want to rename contains nothing besides files of the form [x] - Wikipedia.html, so escaping the dot character is unnecessary in this case. However, when formulating search terms, it is good to be as specific as possible.
The dot character is one of several metacharacters that have a special meaning in regular expressions (see Table 2). The dollar sign ($) at the end of the search expression tells rename to match part of a file name only if the match occurs at the end of the file name.
Table 2
Regular Expression Metacharacters
| Metacharacter | Meaning |
|---|---|
| \ (backslash) |
Escapes the character immediately following the backslash so that the immediately following character is interpreted literally and not as a metacharacter itself. Use two consecutive backslashes (\\) to match a single literal backslash character. |
| . (dot) |
Matches any single character. |
| [and ] (square brackets): |
Matches any one of the characters enclosed within the square brackets. For example, [Ahk7~] matches A, h, k, 7, or ~, but no other characters and no combination of two or more characters. Ranges of characters are also supported; for instance, [A-Z] matches any single uppercase letter, and [A-Za-z0-9] matches any single numeric digit or upper- or lowercase letter. If a caret (^) immediately follows the open square bracket, the matching is inverted, and the square bracket expression will match any character not present within the square brackets; thus, [^A-Z_] matches k, 6, and #, but not K, Z, or an underscore (_). |
| ( and ) (parentheses) |
Combines parts of a regular expression that would normally be considered separate, as well as separates parts that would otherwise be considered one component. For example, (b|c|f)ar would match bar, car, or far, whereas without the parentheses (b|c|far) it would match b, c, or far but not bar or car. Anything within a pair of parentheses is grouped together into a single sub-expression, and other metacharacters will operate upon the parenthesized sub-expression as one unit; so (me)+ will match me, meme, mememe, and so on. |
| ? (question mark) |
Marks the previous character as optional (i.e., the character may either not occur or may occur exactly once). For example, z? matches either z or an empty string, but will not by itself match zz or zzzzzzz. |
| * (asterisk) |
Causes the previous character in the search string to match no matter how many or how few times it occurs in a row, even if it does not occur at all. For example, H* will match H, HH, HHH, HHHHHHHHHH, or even nothing at all. |
| + (plus sign) |
Like the asterisk, causes the previous character in the search string to match no matter how many or how few times it occurs in a row, as long as it occurs at least once. For example, H+ will match H, HH, HHH, HHHHHHHHHH, but not an empty string. |
| { and } (braces) |
Causes the previous character to match if it appears a number of times, that number being between an upper and lower range specified between the braces. For example, k{2,6} matches between two and six letter ks in a row, but not seven or more, not a single k, and not an empty string. k{,6} is equivalent to k{1,6}, and k{3,} matches three or more letter ks in a row. |
| | (pipe) |
Matches either of two (or possibly more) sub-expressions. For example, cat|walrus matches either cat or walrus, (cat|walrus)walk matches either catwalk or walruswalk, and cat|lion|weasel matches any of the words cat, lion, or weasel. |
| ^ (caret) |
Matches the start of a line. This does not match any real character by itself; it just marks that the next character in the search string must occur at the very beginning of the line. As expected, the caret must generally be the first character in the search string. |
| $ (dollar sign) |
Matches the end of a line. As with the caret, this does not match any real character by itself and only informs rename to consider the previous character a match if and only if the previous character is the last character on the line. The dollar sign has another meaning if followed by a digit and/or if it appears in the replacement expression instead of the search expression (see the entry below). |
| $1 thru $9 |
References a specific parenthesized part of the search expression. $1 references whatever was matched by the sub-expression enclosed in the first pair of parentheses in the search expression, $2 references the sub-expression in the second pair of parentheses, and so on. See the section "Using Back References" for more information. |
For example, the file Key Code Qualifier -- Wikipedia.html would be matched by the regular expression I used in Listing 2, but the file Z - Wikipedia.html.gz (which includes an extra trailing .gz) would not be matched. As with the dot character, to match a literal dollar sign character in the file name, the dollar sign must be preceded by a backslash.
You may also specify one or more characters following the final slash in the s/// command. These characters further modify the behavior of the search-and-replace operation, such as disabling case-sensitive matching (see the "s/// Options" box for details on the options supported by the s/// command.)
s/// Options
By adding one or more extra characters to the end of the s/// command, the behavior of the search-and-replace operation can be modified in various ways. Each option is a single character; multiple options may be specified by immediately following one option character by another, such as s/dog/cat/g, s/\.html$/.HTM/i, and s/recieve/receive/gi.
While more than a dozen options are supported, only two options are potentially useful to most users when renaming files. The first, g, instructs rename to replace all occurrences of the search string with the replacement string, not just the first occurrence. The default is to replace only the first occurrence of the search term; this is sufficient in most cases, but not if you want to replace all occurrences of, for example, the word "affect" with "effect" in the file name affect_of_the_affective_initial_affect.txt.
The other potentially useful option, i, enables case-insensitive searching. In other words, rename does not care whether a character in the search string is upper- or lowercase; either type of character will match either type of character in the file name. By default, if a character in the search string is lowercase, the corresponding character in the file name must also be lowercase in order for the search string to match. For example, without the i option, the search term \.html would match the file test1.html, but not test2.HTML or test3.Html. By contrast, with the i option, the same search expression would match all three files. Even if all or part of the search expression were capitalized, it would still work.
For more information on the other options not discussed here, see the Perl documentation [3].
Using Back References
Renaming files using simple search terms and regular expressions is sufficient in most cases. Most of the time, it suffices to simply add or remove a fixed string to each file name, as in the example of the downloaded Wikipedia pages.
However, sometimes it may be useful to rename files in more sophisticated ways. In the following example, as shown in Listing 3, I have a number of logfiles in a directory, all with dates and times in their names. Each file name contains the year, month, day, hour, minute, and second at which the logfile was created, in that order – roughly the convention of ISO 8601, the international format for dates and times.
Listing 3
Logfiles Names with Dates and Times
$ ls -N daemon_20200309_071842 messages_20211213_134327 messages_20230402_093200 syslog_20191013_233611 syslog_20220726_185603
But suppose I were European and I wanted the dates and times formatted in my local date convention, which is the day followed by the month and finally the year. In addition, I want hyphens inserted between each of the date components (day-month-year) and colons inserted between each time component (hours:minutes:seconds), as in syslog_26-07-2022_18:56:03. Listing 4 shows what I want the file names to look like after renaming the files.
Listing 4
Date and Time Logfiles After Renaming
$ ls -N daemon_09-03-2020_07:18:42 messages_13-12-2021_13:43:27 messages_02-04-2023_09:32:00 syslog_13-10-2019_23:36:11 syslog_26-07-2022_18:56:03
Renaming the files in this manner is not possible using just the simple regular expression syntax. For this purpose, you not only need to search for specific parts of the file name, but also reference in the replacement string the matching text of each of those parts. First, you need to search for the year (a four-digit number) followed by the month (a two-digit number) followed by the day (another two-digit number) and then replace it with the third string found by the search (the day) followed by the second string (the month) followed by the first string (the year).
Regular expressions provide a way to reference parts of the search string in the replacement string using back references. To use back references, the portion of the search string to be referenced must first be enclosed in parentheses. Then the parenthesized part of the search string may be back referenced in the replacement string by inserting a dollar sign ($) character followed by an index number into the replacement string.
The following rename command uses back references to accomplish my first task of reordering the components of the dates and also inserts hyphens between the components:
rename 's/([0-9]{4})([0-9]{2})([0-9]{2})/$3-$2-$1/' *Figure 3 illustrates which parts of the search expression are referenced by each back reference. The arrows in the figure point to the referenced parenthesized regions of the search expression.
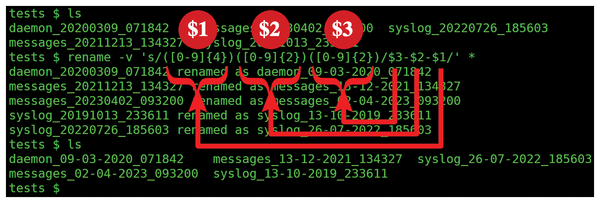 Figure 3: A rename command that uses back references to rearrange the parts of a date string. The annotations illustrate each parenthesized region that is referenced by each back reference in the replacement expression.
Figure 3: A rename command that uses back references to rearrange the parts of a date string. The annotations illustrate each parenthesized region that is referenced by each back reference in the replacement expression.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Canonical Releases Ubuntu 24.04
After a brief pause because of the XZ vulnerability, Ubuntu 24.04 is now available for install.
-
Linux Servers Targeted by Akira Ransomware
A group of bad actors who have already extorted $42 million have their sights set on the Linux platform.
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.