
Smart research using Elasticsearch
More, Please

Websites often offer readers links to articles about similar topics. Using Elasticsearch, the free search engine, is one way to find related documents instantly and automatically.
When people rummage around on the StackOverflow website looking for advice on programming questions, they can find list of links to related topics in the Related section (Figure 1). This helps users if the first search result didn't show what they expected or the located resource is insufficient. According to Gormley and Tong [1], Elasticsearch [2] [3], the free search engine, generates these links on the website in real time from the growing and very impressive collection of 10 million StackOverflow contributions.
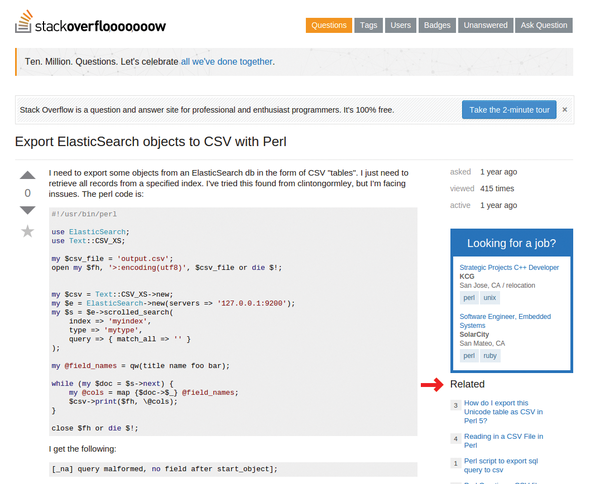 Figure 1: Using Elasticsearch, StackOverflow generates links to similar topics in the Related section.
Figure 1: Using Elasticsearch, StackOverflow generates links to similar topics in the Related section.
Artificial Brain
This isn't actual intelligence at work, because computers still find it difficult to understand the content of a document, meaning they can't find documents with related content. In fact, the algorithm used is based on simple nitpicking – it combines values for word frequency and derives a score from those values.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Container-Based Fedora Hummingbird Designed for Agent-First Builders
Fedora Hummingbird brings the same approach to the host OS as it does to containers to level up security.
-
Linux kernel Developers Considering a Kill Switch
With the rise of Linux vulnerabilities, the kernel developers are now considering adding a component that could help temporarily mitigate against them… in the form of a kill switch.
-
Fedora 44 Now Gaming Ready
The latest version of Fedora has been released with gaming support.
-
Manjaro 26.1 Preview Unveils New Features
The latest Manjaro 26.1 preview has been released with new desktop versions, a new kernel, and more.
-
Microsoft Issues Warning About Linux Vulnerability
The company behind Windows has released information about a flaw that affects millions of Linux systems.
-
Is AI Coming to Your Ubuntu Desktop?
According to the VP of Engineering at Canonical, AI could soon be added to the Ubuntu desktop distribution.
-
Framework Laptop 13 Pro Competes with the Best
Framework has released what might be considered the MacBook of Linux devices.
-
The Latest CachyOS Features Supercharged Kernel
The latest release of CachyOS brings with it an enhanced version of the latest Linux kernel.
-
Kernel 7.0 Is a Bit More Rusty
Linux kernel 7.0 has been released for general availability, with Rust finally getting its due.
-
France Says "Au Revoir" to Microsoft
In a move that should surprise no one, France announced plans to reduce its reliance on US technology, and Microsoft Windows is the first to get the boot.