
A bag o' tricks from the Perlmeister
Undercover Information

If you have been programming for decades, you've likely gathered a personal bag of tricks and best practices over the years – much like this treasure trove from the Perlmeister.
For each new Perl project – and I launch several every week – it is necessary to first prime the working environment. After all, you don't want a pile of spaghetti scripts lying around that nobody can maintain later. A number of template generators are available on CPAN. My attention was recently drawn to App::Skeletor, which uses template modules to adapt to local conditions. Without further ado, I wrote Skeletor::Template::Quick to adapt the original to my needs and uploaded the results to CPAN.
If you store the author info, as shown in Figure 1, in the ~/.skeletor.yml file in your home directory and, after installing the Template module from CPAN, run the skel Foo::Bar command, you can look forward to instantly having a handful of predefined files for a new CPAN distribution dumped into a new directory named Foo-Bar. Other recommended tools for this scaffolding work would be the built-in Perl tool h2xs or the CPAN Module::Starter module.
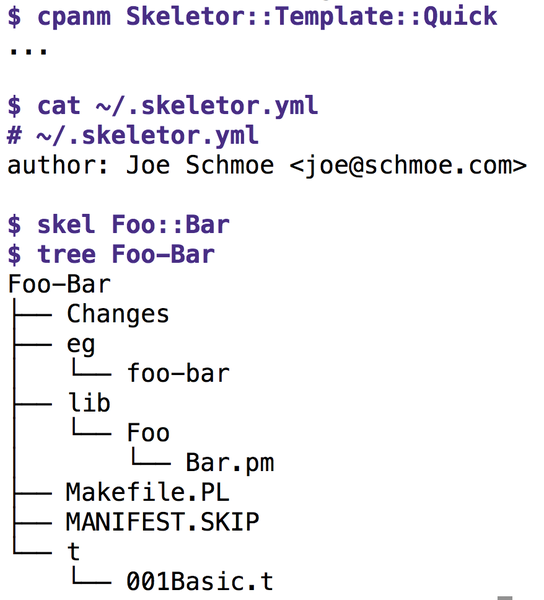 Figure 1: Skeletor produces the raw skeleton for a new CPAN module.
Figure 1: Skeletor produces the raw skeleton for a new CPAN module.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
The Next Linux Kernel Turns 7.0
Linus Torvalds has announced that after Linux kernel 6.19, we'll finally reach the 7.0 iteration stage.
-
Linux From Scratch Drops SysVinit Support
LFS will no longer support SysVinit.
-
LibreOffice 26.2 Now Available
With new features, improvements, and bug fixes, LibreOffice 26.2 delivers a modern, polished office suite without compromise.
-
Linux Kernel Project Releases Project Continuity Document
What happens to Linux when there's no Linus? It's a question many of us have asked over the years, and it seems it's also on the minds of the Linux kernel project.
-
Mecha Systems Introduces Linux Handheld
Mecha Systems has revealed its Mecha Comet, a new handheld computer powered by – you guessed it – Linux.
-
MX Linux 25.1 Features Dual Init System ISO
The latest release of MX Linux caters to lovers of two different init systems and even offers instructions on how to transition.
-
Photoshop on Linux?
A developer has patched Wine so that it'll run specific versions of Photoshop that depend on Adobe Creative Cloud.
-
Linux Mint 22.3 Now Available with New Tools
Linux Mint 22.3 has been released with a pair of new tools for system admins and some pretty cool new features.
-
New Linux Malware Targets Cloud-Based Linux Installations
VoidLink, a new Linux malware, should be of real concern because of its stealth and customization.
-
Say Goodbye to Middle-Mouse Paste
Both Gnome and Firefox have proposed getting rid of a long-time favorite Linux feature.