
Of lakes and sparks – How Hadoop 2 got it right
In a recent story on the PCWorld website titled "Hadoop successor sparks a data analysis evolution," the author predicts that Apache Spark will supplant Hadoop in 2015 for Big Data processing [1]. The article is so full of mis- (or dis-)information that it really is a disservice to the industry. To provide an accurate picture of Spark and Hadoop, several topics need to be explored in detail.
First, like any article on "Big Data," is it important to define exactly what you are talking about. The term "Big Data" is a marketing buzz-phase that has as much meaning as things like "Tall Mountain" or "Fast Car." Second, the concept of the data lake (less of a buzz-phrase and more descriptive than Big Data) needs to be defined. Third, Hadoop version 2 is more than a MapReduce engine. Indeed, if there is anything to take away from this article it is the message in Figure 1. And, finally, how Apache Spark neatly fits into the Hadoop ecosystem will be explained.
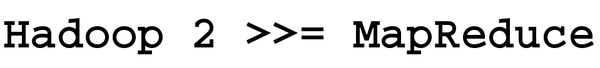 Figure 1: Hadoop version 2 is much more than MapReduce.
Figure 1: Hadoop version 2 is much more than MapReduce.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
System76 Retools Thelio Desktop
The new Thelio Mira has landed with improved performance, repairability, and front-facing ports alongside a high-quality tempered glass facade.
-
Some Linux Distros Skirt Age Verification Laws
After California introduced an age verification law recently, open source operating system developers have had to get creative with how they deal with it.
-
UN Creates Open Source Portal
In a quest to strengthen open source collaboration, the United Nations Office of Information and Communications Technology has created a new portal.
-
Latest Linux Kernel RC Contains Changes Galore
Linux kernel 7.0-rc3 includes more changes than have been made in a single release in recent history.
-
Nitrux 6.0 Now Ready to Rock Your World
The latest iteration of the Debian-based distribution includes all kinds of newness.
-
Linux Foundation Reports that Open Source Delivers Better ROI
In a report that may surprise no one in the Linux community, the Linux Foundation found that businesses are finding a 5X return on investment with open source software.
-
Keep Android Open
Google has announced that, soon, anyone looking to develop Android apps will have to first register centrally with Google.
-
Kernel 7.0 Now in Testing
Linus Torvalds has announced the first Release Candidate (RC) for the 7.x kernel is available for those who want to test it.
-
Introducing matrixOS, an Immutable Gentoo-Based Linux Distro
It was only a matter of time before a developer decided one of the most challenging Linux distributions needed to be immutable.
-
Chaos Comes to KDE in KaOS
KaOS devs are making a major change to the distribution, and it all comes down to one system.