
Bringing Up Clouds
First as a buzzword and then as a commodity, the cloud lives the typical life of an IT industry phenomenon. This means that running something (but usually Linux) in a cloud is a thing you now do more often than not. From a user perspective, it's simple: You click a button on the cloud provider's dashboard and get your virtual machine (VM) running within a minute.
This is drastically different from what you do on your desktop. Here, you insert the DVD or plug in a USB pen drive and spawn the installer. Be it an old-school, text-based or a slick GUI installer, it typically asks you some questions (Figure 1). Which locale do you want to use? What's your computer's hostname? What's your time zone? How do you want your user account named? Which password do you want to use? You may not even notice these questions, because installation takes a quarter of an hour or more, and you spend most of this time sipping coffee or chatting with friends. Yet these questions are essential for the system's operation. Without a password, you won't be able to log in. Or, even worse, everyone will be able to.
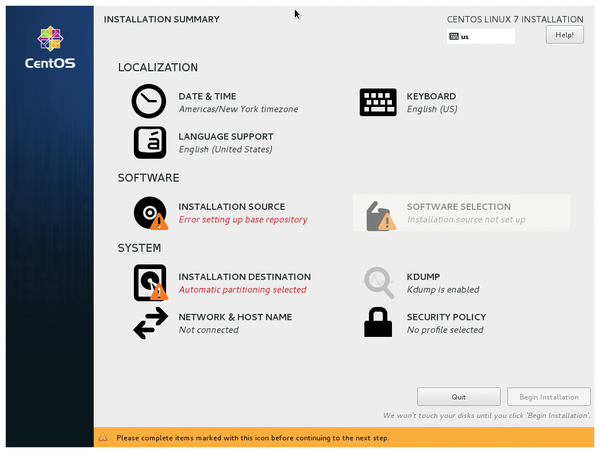 Figure 1: The Anaconda installer makes you answer some questions before you can install anything.
Figure 1: The Anaconda installer makes you answer some questions before you can install anything.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
UN Creates Open Source Portal
In a quest to strengthen open source collaboration, the United Nations Office of Information and Communications Technology has created a new portal.
-
Latest Linux Kernel RC Contains Changes Galore
Linux kernel 7.0-rc3 includes more changes than have been made in a single release in recent history.
-
Nitrux 6.0 Now Ready to Rock Your World
The latest iteration of the Debian-based distribution includes all kinds of newness.
-
Linux Foundation Reports that Open Source Delivers Better ROI
In a report that may surprise no one in the Linux community, the Linux Foundation found that businesses are finding a 5X return on investment with open source software.
-
Keep Android Open
Google has announced that, soon, anyone looking to develop Android apps will have to first register centrally with Google.
-
Kernel 7.0 Now in Testing
Linus Torvalds has announced the first Release Candidate (RC) for the 7.x kernel is available for those who want to test it.
-
Introducing matrixOS, an Immutable Gentoo-Based Linux Distro
It was only a matter of time before a developer decided one of the most challenging Linux distributions needed to be immutable.
-
Chaos Comes to KDE in KaOS
KaOS devs are making a major change to the distribution, and it all comes down to one system.
-
New Linux Botnet Discovered
The SSHStalker botnet uses IRC C2 to control systems via legacy Linux kernel exploits.
-
The Next Linux Kernel Turns 7.0
Linus Torvalds has announced that after Linux kernel 6.19, we'll finally reach the 7.0 iteration stage.