
Use Google Refine to Massage Your Data

Productivity Sauce
Google Refine is an immensely powerful tool for dealing with "messy" data, and it sports a myriad of advanced features for massaging and analyzing complex data sets. However, that doesn't mean Google Refine can't be used to solve more mundane problems.
Of course, before you can put Google Refine to some use, you have to install it. First off, make sure that the Java Runtime Environment is installed on your machine. Grab then the latest version of Google Refine from the project's Web site and unpack the downloaded .tar.gz archive. In the terminal, switch to the resulting directory and start the application using the following commands:
cd google-refine ./refine
This starts the application and automatically opens it in the default browser.
To see what you can accomplish with Google Refine, let's take a look at a real world example. If you, like me, are an avid book reader and Kindle 3 user, you might have hundreds of highlights stored in the My Clipping.txt file. Having all the highlights in a single text file is not very practical, so it would be great to convert data in the My Clipping.txt file into a tab-separated format, so you can import them into a database. The problem is that the data in the My Clipping.txt file is not particularly well structured. Here, take a look at how highlights are stored in the file:
The Shallows: What the Internet Is Doing to Our Brains (Nicholas Carr) - Highlight Loc. 2106-9 | Added on Saturday, October 23, 2010, 11:24 PM It is the very fact that book reading “understimulates the senses” that makes the activity so intellectually rewarding. By allowing us to filter out distractions, to quiet the problem-solving functions of the frontal lobes, deep reading becomes a form of deep thinking. The mind of the experienced book reader is a calm mind, not a buzzing one. When it comes to the firing of our neurons, it’s a mistake to assume that more is better. ========== The Shallows: What the Internet Is Doing to Our Brains (Nicholas Carr) - Highlight Loc. 2117-18 | Added on Saturday, October 23, 2010, 11:26 PM If working memory is the mind’s scratch pad, then long-term memory is its filing system. ==========
This is where Google Refine can come in rather handy, allowing you to massage the data into a usable form with a minimum of effort. Here's how it works. Start with creating a new project in Google Refine. Choose the My Clipping.txt file as the project's data file, untick the Split into columns check box, set Header lines to 0, and press the Create Project button. This creates a new project, where each entry in the My Clipping.txt file is treated as a separate row.
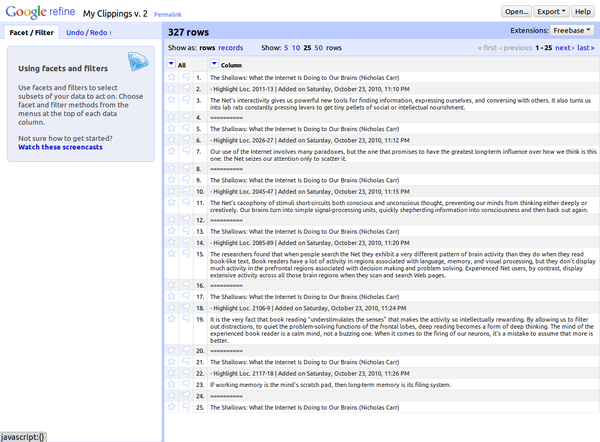
Fortunately, Google Refine provides an elegant way of turning rows into columns. Click on the menu next to the Column entry and choose the Transpose | Cell in rows into columns command. When prompted, specify the number of rows you want to transpose (in this case, it's 4), and press OK. Google Refine then processes the rows and moves them into the appropriate columns. The hardest part is over, and there are just a few simple things left for you to do.

Obviously, Column 4 is useless, so you can safely delete it using the Edit Column | Remove this column command. It also makes sense to give the columns more descriptive names, which can be done using the Edit Column | Rename this column command. And you can rearrange columns using the Edit Column | Move column to beginning / Move column to end / Move column left / Move column right commands. Finally, you can use the Export button to save the massaged data in a variety of formats.
Comments
comments powered by DisqusSubscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Yet Another Linux Kernel Vulnerability Discovered
Affecting millions of systems, a kernel flaw discovered by Qualys could allow users to gain root privileges.
-
Ubuntu 26.10 to Include Ubuntu Certified Hardware Check
If you've ever wondered if your laptop or PC is officially certified to run Ubuntu, that curiosity will soon be met.
-
Substantial Update to IPFire Now Available
The lastest version of IPFire features a fundamental change to how the system handles DNS.
-
Gnome Working on Test Center App to Make Testing Easier
It's now possible to test experimental features on the Gnome desktop without worrying that you'll break things.
-
New Vulnerability Discovered in Linux Kernel
Hiding out for nearly 15 years, the Ghostlock vulnerability allows a standard logged-in user to gain root privileges.
-
New Linux Flaw Lets Attackers Escape VMs
A 16-year-old vulnerability allows an attacker to escape a virtual machine, gain access to the host, and execute malicious code.
-
Hannah Montana Linux Is Back!
Developer Noah Cagle decided the world needed the once obscure but beloved Linux distribution and gave it a decidedly pink refresh.
-
System76 Refreshes the Lemur Laptop
If you're looking for a laptop with tons of power and battery, look no further than the latest iteration of the System76 Lemur Pro.
-
More than 43 Million Lines of Code in Linux Kernel 7.2
Using the cloc utility, Michael Larabel of Phoronix discovered that Linux kernel 7.2 has over 43 million lines of code.
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.
Dragging and dropping Columns is supported as well
Click the drop-down arrow on first column ALL --> Edit columns --> Reorder columns...
You then have a popup dialog box to drag and drop the columns themselves. Great for those datasets that have many, many columns to deal with.
And if you have too many columns and run into visibility hell, you can always "hide" columns using Collapse this column and then "unhide" all the columns with ALL --> View --> Expand all columns...