
Bringing Up Clouds
Core Technology

VM instances in the cloud are different beasts, even if they start off as a single image. Discover how they get their configuration in this month's Core Technologies.
First as a buzzword and then as a commodity, the cloud lives the typical life of an IT industry phenomenon. This means that running something (but usually Linux) in a cloud is a thing you now do more often than not. From a user perspective, it's simple: You click a button on the cloud provider's dashboard and get your virtual machine (VM) running within a minute.
This is drastically different from what you do on your desktop. Here, you insert the DVD or plug in a USB pen drive and spawn the installer. Be it an old-school, text-based or a slick GUI installer, it typically asks you some questions (Figure 1). Which locale do you want to use? What's your computer's hostname? What's your time zone? How do you want your user account named? Which password do you want to use? You may not even notice these questions, because installation takes a quarter of an hour or more, and you spend most of this time sipping coffee or chatting with friends. Yet these questions are essential for the system's operation. Without a password, you won't be able to log in. Or, even worse, everyone will be able to.
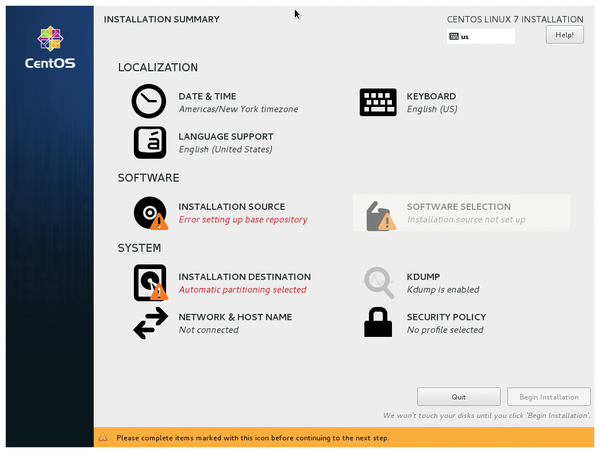 Figure 1: The Anaconda installer makes you answer some questions before you can install anything.
Figure 1: The Anaconda installer makes you answer some questions before you can install anything.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Substantial Update to IPFire Now Available
The lastest version of IPFire features a fundamental change to how the system handles DNS.
-
Gnome Working on Test Center App to Make Testing Easier
It's now possible to test experimental features on the Gnome desktop without worrying that you'll break things.
-
New Vulnerability Discovered in Linux Kernel
Hiding out for nearly 15 years, the Ghostlock vulnerability allows a standard logged-in user to gain root privileges.
-
New Linux Flaw Lets Attackers Escape VMs
A 16-year-old vulnerability allows an attacker to escape a virtual machine, gain access to the host, and execute malicious code.
-
Hannah Montana Linux Is Back!
Developer Noah Cagle decided the world needed the once obscure but beloved Linux distribution and gave it a decidedly pink refresh.
-
System76 Refreshes the Lemur Laptop
If you're looking for a laptop with tons of power and battery, look no further than the latest iteration of the System76 Lemur Pro.
-
More than 43 Million Lines of Code in Linux Kernel 7.2
Using the cloc utility, Michael Larabel of Phoronix discovered that Linux kernel 7.2 has over 43 million lines of code.
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.
-
Linux Gamers May Soon See Less Mouse Lag in KDE Plasma
Gamers using KDE’s Plasma desktop have been suffering from a slight input delay in mouse movement that could lead to getting fragged.
-
Three Lines of Code Improve Linux Storage Performance
A developer changed three lines of code, giving Linux storage performance a 5% bump.