
Extract Pages from a PDF File with a GUI Bash Script

Productivity Sauce
Every now and then I need to extract individual pages from PDF files. Usually, I use the following one-liner that does the trick:
pdftk A=foo.pdf cat A5-15 output pages_5-15.pdf
This command uses the pdftk toolkit to pull a range of pages (in this case, from 5 to 15) out of the specified PDF file (foo.pdf). Recently, though, I stumbled upon a handy Bash script that generates a simple graphical interface for extracting pages from a PDF file.
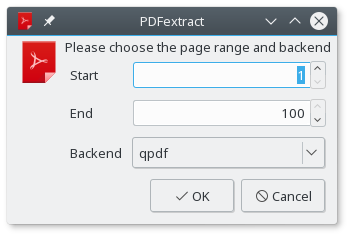
Although the script is posted on the Ask Ubuntu forum, it should work on any distribution that has any of the supported PDF utilities (qpdf, ghostscript, or cpdf) and the yad GUI tool installed. Copy and paste the script into a text file, and save it under the extract-pages.sh name. Make the script executable using the chmod +x extract-pages.sh command. Run the script in the terminal using the ./extract-pages.sh command followed by the path to the input PDF file (e.g., ./extract-pages.sh foo.pdf), specify the desired page range, select the back-end PDF processing tool, and hit OK.
comments powered by DisqusSubscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
More than 43 Million Lines of Code in Linux Kernel 7.2
Using the cloc utility, Michael Larabel of Phoronix discovered that Linux kernel 7.2 has over 43 million lines of code.
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.
-
Linux Gamers May Soon See Less Mouse Lag in KDE Plasma
Gamers using KDE’s Plasma desktop have been suffering from a slight input delay in mouse movement that could lead to getting fragged.
-
Three Lines of Code Improve Linux Storage Performance
A developer changed three lines of code, giving Linux storage performance a 5% bump.
-
AUR Hit Again with Malicious Packages
Once again the Arch User Repository is plagued by a high volume of malicious packages.
-
Alpine Linux 3.24 Features Fresh Desktops and a Newer Kernel
If you're a fan of Alpine Linux, it's time to upgrade because the latest version has been released with KDE Plasma 6.6, Gnome 50, and Linux kernel 6.18 LTS.
-
EU Open Source Strategy Plays Key Role in Tech Sovereignty Package
Comprehensive measures adopted by the European Commission aim to reduce dependency on non-EU countries.
-
Linux Foundation Report Indicates AI Driving Tech Hiring
Within growing security and skills gaps, AI has been found to be a positive driving force behind tech hiring trends in Europe.
-
United Nations Open Source Portal Goes Live
A new open source portal seeks to coordinate and scale open source efforts across the United Nations system.
-
KDE Linux Drops AUR
KDE Linux developers have dropped the Arch User Repository from the build pipeline due to security concerns; other distributions should consider doing the same.