
Parallel Programming with OpenMP
If you bought a new computer recently, or if you are wading through advertising material because you plan to buy a computer soon, you will be familiar with terms such as "Dual Core" and "Quad Core." A whole new crop of consumer computers includes two- or even four-core CPUs, taking the humble PC into what used to be the domain of high-end servers and workstations. But just because you have a multi-processor system doesn't mean all the processors are working hard.
In reality, often only one processor is busy. Figure 1 shows the top program output for Xaos, a fractal calculation program. The program seems to be using 100 percent of the CPU. But appearances can be deceptive: The computer's actual load is just 60 percent.
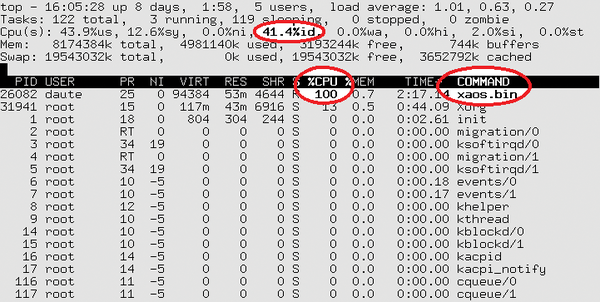 Figure 1: By default, top shows the total load for all CPUs …
Figure 1: By default, top shows the total load for all CPUs …
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
United Nations Open Source Portal Goes Live
A new open source portal seeks to coordinate and scale open source efforts across the United Nations system.
-
KDE Linux Drops AUR
KDE Linux developers have dropped the Arch User Repository from the build pipeline due to security concerns; other distributions should consider doing the same.
-
California May Exempt Linux from Its Age-Verification Law
After backlash from the Linux community, California may be backing off on its promise to force all operating systems to verify age, but one platform may still have to comply.
-
Another Logic Bug Found in Linux Kernel
Qualys has discovered a vulnerability in the Linux kernel that can be used to elevate standard user privileges.
-
Ubuntu Core 26 Offers Game-Changing Enterprise Features
Ubuntu Core 26 could be a game-changer for organizations looking for increased security and reliability.
-
AI Flooding the Linux Kernel Security Mailing List
AI is giving Linus Torvalds a headache, but not in the way you might think.
-
Top Priorities for Open Source Pros Seeking a New Job
Professional fulfillment tops the list, according to LPI report.
-
Container-Based Fedora Hummingbird Designed for Agent-First Builders
Fedora Hummingbird brings the same approach to the host OS as it does to containers to level up security.
-
Linux kernel Developers Considering a Kill Switch
With the rise of Linux vulnerabilities, the kernel developers are now considering adding a component that could help temporarily mitigate against them… in the form of a kill switch.
-
Fedora 44 Now Gaming Ready
The latest version of Fedora has been released with gaming support.