
Programming for the Amazon EC2 cloud
Lofty Code

© Iakov Kalinin, Fotolia
We show you some techniques for harnessing the benefits of cloud technology.
Everyone is talking about the promise of cloud computing, but when it comes to implementation, some of the early adopters have simply deployed cloud services by copying older methods used in conventional environments. In fact, the cloud can do much more for you. Running sites on EC2 is easy, but really making use of the scalability and flexibility of cloud computing requires a new approach (Figure 1). In this article, I describe some techniques for building the benefits of cloud computing into your infrastructure. Although I use examples based on the Ruby language and Amazon's EC2 cloud environment, these concepts also apply to other languages and cloud vendors.
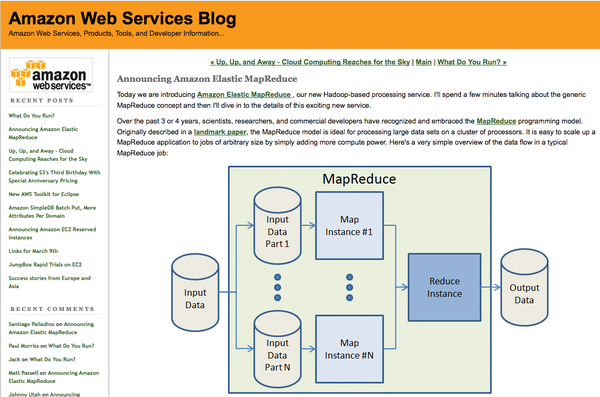 Figure 1: Amazon recently added MapReduce to their list of services. As if cache, computing, and queues aren't enough, now you can run huge, distributed tasks.
Figure 1: Amazon recently added MapReduce to their list of services. As if cache, computing, and queues aren't enough, now you can run huge, distributed tasks.
Keep It Static
In the cloud, you don't need everything to go through your server (even if it is virtual). You don't need a virtual server for serving files, managing queues, and storing shared data. Dedicated services can perform these tasks, and using them will help you get your applications working better in the cloud.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Substantial Update to IPFire Now Available
The lastest version of IPFire features a fundamental change to how the system handles DNS.
-
Gnome Working on Test Center App to Make Testing Easier
It's now possible to test experimental features on the Gnome desktop without worrying that you'll break things.
-
New Vulnerability Discovered in Linux Kernel
Hiding out for nearly 15 years, the Ghostlock vulnerability allows a standard logged-in user to gain root privileges.
-
New Linux Flaw Lets Attackers Escape VMs
A 16-year-old vulnerability allows an attacker to escape a virtual machine, gain access to the host, and execute malicious code.
-
Hannah Montana Linux Is Back!
Developer Noah Cagle decided the world needed the once obscure but beloved Linux distribution and gave it a decidedly pink refresh.
-
System76 Refreshes the Lemur Laptop
If you're looking for a laptop with tons of power and battery, look no further than the latest iteration of the System76 Lemur Pro.
-
More than 43 Million Lines of Code in Linux Kernel 7.2
Using the cloc utility, Michael Larabel of Phoronix discovered that Linux kernel 7.2 has over 43 million lines of code.
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.
-
Linux Gamers May Soon See Less Mouse Lag in KDE Plasma
Gamers using KDE’s Plasma desktop have been suffering from a slight input delay in mouse movement that could lead to getting fragged.
-
Three Lines of Code Improve Linux Storage Performance
A developer changed three lines of code, giving Linux storage performance a 5% bump.