
Bringing Up Clouds
Core Technology

VM instances in the cloud are different beasts, even if they start off as a single image. Discover how they get their configuration in this month's Core Technologies.
First as a buzzword and then as a commodity, the cloud lives the typical life of an IT industry phenomenon. This means that running something (but usually Linux) in a cloud is a thing you now do more often than not. From a user perspective, it's simple: You click a button on the cloud provider's dashboard and get your virtual machine (VM) running within a minute.
This is drastically different from what you do on your desktop. Here, you insert the DVD or plug in a USB pen drive and spawn the installer. Be it an old-school, text-based or a slick GUI installer, it typically asks you some questions (Figure 1). Which locale do you want to use? What's your computer's hostname? What's your time zone? How do you want your user account named? Which password do you want to use? You may not even notice these questions, because installation takes a quarter of an hour or more, and you spend most of this time sipping coffee or chatting with friends. Yet these questions are essential for the system's operation. Without a password, you won't be able to log in. Or, even worse, everyone will be able to.
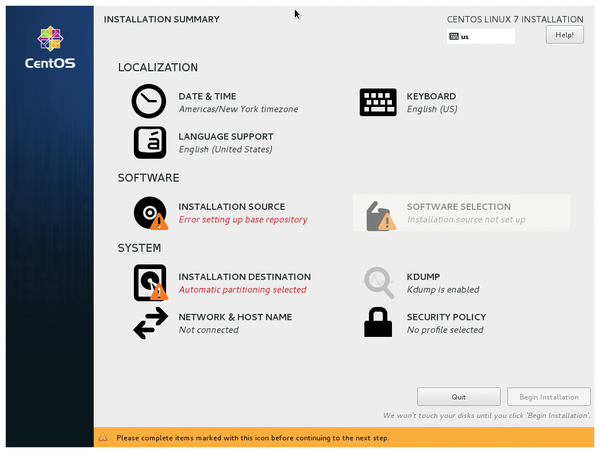 Figure 1: The Anaconda installer makes you answer some questions before you can install anything.
Figure 1: The Anaconda installer makes you answer some questions before you can install anything.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Linux Foundation Report Indicates AI Driving Tech Hiring
Within growing security and skills gaps, AI has been found to be a positive driving force behind tech hiring trends in Europe.
-
United Nations Open Source Portal Goes Live
A new open source portal seeks to coordinate and scale open source efforts across the United Nations system.
-
KDE Linux Drops AUR
KDE Linux developers have dropped the Arch User Repository from the build pipeline due to security concerns; other distributions should consider doing the same.
-
California May Exempt Linux from Its Age-Verification Law
After backlash from the Linux community, California may be backing off on its promise to force all operating systems to verify age, but one platform may still have to comply.
-
Another Logic Bug Found in Linux Kernel
Qualys has discovered a vulnerability in the Linux kernel that can be used to elevate standard user privileges.
-
Ubuntu Core 26 Offers Game-Changing Enterprise Features
Ubuntu Core 26 could be a game-changer for organizations looking for increased security and reliability.
-
AI Flooding the Linux Kernel Security Mailing List
AI is giving Linus Torvalds a headache, but not in the way you might think.
-
Top Priorities for Open Source Pros Seeking a New Job
Professional fulfillment tops the list, according to LPI report.
-
Container-Based Fedora Hummingbird Designed for Agent-First Builders
Fedora Hummingbird brings the same approach to the host OS as it does to containers to level up security.
-
Linux kernel Developers Considering a Kill Switch
With the rise of Linux vulnerabilities, the kernel developers are now considering adding a component that could help temporarily mitigate against them… in the form of a kill switch.