
Redirect data streams with pipes
Many users are only familiar with pipes as links between multiple flows, but they can do much more than that. Pipes can help you transfer data between computers. In this article, I will show you how to use pipes to redirect data streams in the shell.
Channels
Whenever a process starts under Linux, it is automatically assigned three channels. These channels have system assignments that let you address them, and each has a starting and end point. Channel 0 (STDIN) reads data, channel 1 (STDOUT) outputs data, and channel 2 (STDERR) outputs any error messages. Channel 2 typically points to the same device as channel 1 (Figure 1).
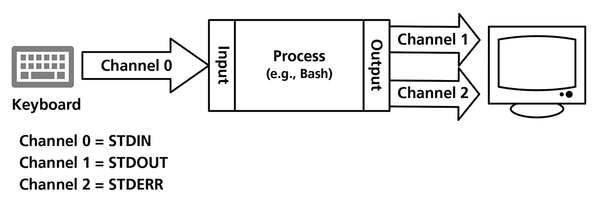 Figure 1: The shell reads input from the keyboard (STDIN, channel 0) and outputs the results on screen (STDOUT, channel 1). Error messages are displayed via STDERR (channel 2).
Figure 1: The shell reads input from the keyboard (STDIN, channel 0) and outputs the results on screen (STDOUT, channel 1). Error messages are displayed via STDERR (channel 2).
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Plasma Ends LTS Releases
The KDE Plasma development team is doing away with the LTS releases for a good reason.
-
Arch Linux Available for Windows Subsystem for Linux
If you've ever wanted to use a rolling release distribution with WSL, now's your chance.
-
System76 Releases COSMIC Alpha 7
With scores of bug fixes and a really cool workspaces feature, COSMIC is looking to soon migrate from alpha to beta.
-
OpenMandriva Lx 6.0 Available for Installation
The latest release of OpenMandriva has arrived with a new kernel, an updated Plasma desktop, and a server edition.
-
TrueNAS 25.04 Arrives with Thousands of Changes
One of the most popular Linux-based NAS solutions has rolled out the latest edition, based on Ubuntu 25.04.
-
Fedora 42 Available with Two New Spins
The latest release from the Fedora Project includes the usual updates, a new kernel, an official KDE Plasma spin, and a new System76 spin.
-
So Long, ArcoLinux
The ArcoLinux distribution is the latest Linux distribution to shut down.
-
What Open Source Pros Look for in a Job Role
Learn what professionals in technical and non-technical roles say is most important when seeking a new position.
-
Asahi Linux Runs into Issues with M4 Support
Due to Apple Silicon changes, the Asahi Linux project is at odds with adding support for the M4 chips.
-
Plasma 6.3.4 Now Available
Although not a major release, Plasma 6.3.4 does fix some bugs and offer a subtle change for the Plasma sidebar.