
Calculating Probability
Perl – Think Again

To tackle mathematical problems with conditional probabilities, math buffs rely on Bayes' formula or discrete distributions, generated by short Perl scripts.
Features
The Monty Hall problem is loved by statisticians around the world [1]. You might be familiar with this puzzle, in which a game show host offers a contestant a choice of three doors – behind one door is a prize, but the other two doors only reveal goats. After the contestant chooses a door, the TV host opens a different door, revealing a goat, and asks the candidate to reconsider (Figure 1). Who would have thought that probabilities in a static television studio could change so dramatically just because the host opens a door without a prize?
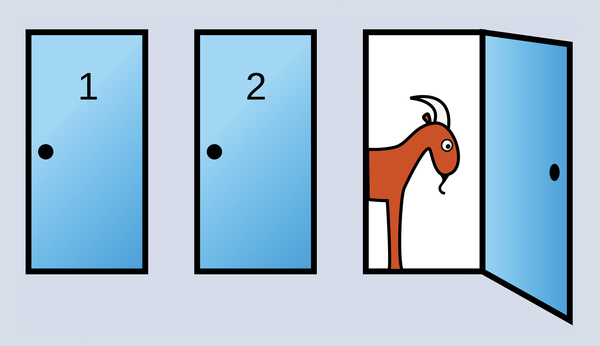 Figure 1: Hoping to win the car, the contestant chooses door 1. The host, who knows which door leads to the car, then opens door 3, revealing a goat. He offers the contestant the option of picking another door. Does it make sense for the contestant to change their mind and go for door 2? (Source: Wikipedia)
Figure 1: Hoping to win the car, the contestant chooses door 1. The host, who knows which door leads to the car, then opens door 3, revealing a goat. He offers the contestant the option of picking another door. Does it make sense for the contestant to change their mind and go for door 2? (Source: Wikipedia)
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.
-
Linux Gamers May Soon See Less Mouse Lag in KDE Plasma
Gamers using KDE’s Plasma desktop have been suffering from a slight input delay in mouse movement that could lead to getting fragged.
-
Three Lines of Code Improve Linux Storage Performance
A developer changed three lines of code, giving Linux storage performance a 5% bump.
-
AUR Hit Again with Malicious Packages
Once again the Arch User Repository is plagued by a high volume of malicious packages.
-
Alpine Linux 3.24 Features Fresh Desktops and a Newer Kernel
If you're a fan of Alpine Linux, it's time to upgrade because the latest version has been released with KDE Plasma 6.6, Gnome 50, and Linux kernel 6.18 LTS.
-
EU Open Source Strategy Plays Key Role in Tech Sovereignty Package
Comprehensive measures adopted by the European Commission aim to reduce dependency on non-EU countries.
-
Linux Foundation Report Indicates AI Driving Tech Hiring
Within growing security and skills gaps, AI has been found to be a positive driving force behind tech hiring trends in Europe.
-
United Nations Open Source Portal Goes Live
A new open source portal seeks to coordinate and scale open source efforts across the United Nations system.
-
KDE Linux Drops AUR
KDE Linux developers have dropped the Arch User Repository from the build pipeline due to security concerns; other distributions should consider doing the same.
-
California May Exempt Linux from Its Age-Verification Law
After backlash from the Linux community, California may be backing off on its promise to force all operating systems to verify age, but one platform may still have to comply.