
Collecting Data from Web Pages with OutWit

Productivity Sauce
Web scraping is a clever idea, but extracting data from a Web page manually can be a real chore. The new OutWit extension provides a solution to this problem. Better yet, it allows you to save and export the scraped data, which makes it a great research tool. Although the extension is still at a very early stage of development, it has the potential to turn your favorite browser into a powerful tool for extracting and organizing data. The current version already boasts an impressive list of features, including data structure recognition, page and image link extraction, e-mail extraction, table and list extraction, and more.
Although OutWit is a rather advanced tool, using it for simple Web scraping is not particularly difficult. Let's say you want to extract data from the Population of the 5 largest cities in the EU table and export the data for use in a Calc spreadsheet. Press the OutWit button in the Firefox toolbar to open the OutWit Hub window. The left pane contains a tree of data types supported by the OutWit Hub. Navigate to page -> data -> tables, and you should see the data from the tables on the Wikipedia page. Locate and select the rows containing the city data (see screenshot below) and drag them onto the Catch pane at the bottom.
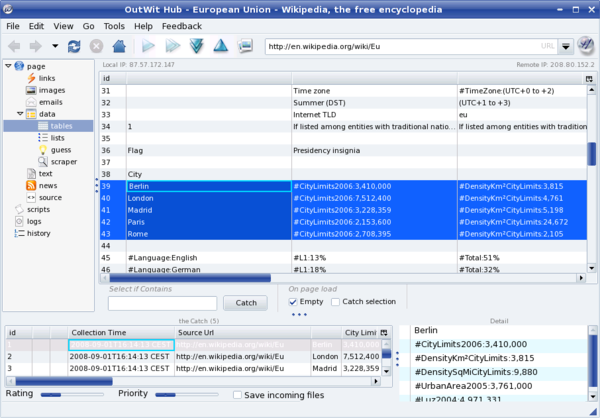
To save the selected data, choose the File -> Save Catch as command. To export the data for use in a spreadsheet, select all the rows in the Catch pane, right-click on the selection, and choose the Export Selection as command. OutWit can export the data in the Excel format only, but since OpenOffice.org Calc can read .xls files, that's not a big issue. In a similar manner, you can collect other types of data, including lists, email addresses, RSS feeds, images, and much more.
OutWit is actually more than just a mere Firefox extension. It is a platform that allows you to create your own Web data collection solutions called outfits. In fact, the OutWit Hub is an outfit built upon the OutWit kernel. Besides catching all sorts of data from a Web page, you can use OutWit Hub to create your own scrapers, and the following post on the OutWit blog shows you how to do that.
Comments
comments powered by DisqusSubscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
New Linux Flaw Lets Attackers Escape VMs
A 16-year-old vulnerability allows an attacker to escape a virtual machine, gain access to the host, and execute malicious code.
-
Hannah Montana Linux Is Back!
Developer Noah Cagle decided the world needed the once obscure but beloved Linux distribution and gave it a decidedly pink refresh.
-
System76 Refreshes the Lemur Laptop
If you're looking for a laptop with tons of power and battery, look no further than the latest iteration of the System76 Lemur Pro.
-
More than 43 Million Lines of Code in Linux Kernel 7.2
Using the cloc utility, Michael Larabel of Phoronix discovered that Linux kernel 7.2 has over 43 million lines of code.
-
Kubuntu Focus Goes Ultra
The Kubuntu Focus team has upped the performance ante of its M2 and Zr laptops with the latest, greatest CPUs from Intel.
-
Linux Gamers May Soon See Less Mouse Lag in KDE Plasma
Gamers using KDE’s Plasma desktop have been suffering from a slight input delay in mouse movement that could lead to getting fragged.
-
Three Lines of Code Improve Linux Storage Performance
A developer changed three lines of code, giving Linux storage performance a 5% bump.
-
AUR Hit Again with Malicious Packages
Once again the Arch User Repository is plagued by a high volume of malicious packages.
-
Alpine Linux 3.24 Features Fresh Desktops and a Newer Kernel
If you're a fan of Alpine Linux, it's time to upgrade because the latest version has been released with KDE Plasma 6.6, Gnome 50, and Linux kernel 6.18 LTS.
-
EU Open Source Strategy Plays Key Role in Tech Sovereignty Package
Comprehensive measures adopted by the European Commission aim to reduce dependency on non-EU countries.
World coins
INCREDIBLE STUFF!
Very cool FF3 version
Great Add-On! Thanks for the tip.
Outwit
I'll stick to good old scrapbook for now...