
Getting started with the ELK Stack monitoring solution
Elk Hunting

© Photo by David Santoyo on Unsplash
ELK Stack is a powerful monitoring system known for efficient log management and versatile visualization. This hands-on workshop will help you take your first steps with setting up your own ELK Stack monitoring solution.
Today's networks require a monitoring solution with industrial-strength log management and analytics. One option that has gained popularity in recent years is ELK stack [1]. The free and open source ELK Stack collection is maintained by a company called Elastic. (According to the website, the company has recently changed the name of the project to Elastic Stack, but the previous name is still in common usage.) ELK Stack is not a single tool but a collection of tools (Figure 1). The ELK acronym highlights the importance of the collection's three most important utilities. At the heart of the stack, Elasticsearch collects and maintains data, providing an engine, based on Apache Lucene, for searching through it. Logstash serves as the log processing pipeline, collecting data from a multitude of sources, transforming it, then sending it to a chosen "stash." (Keep in mind that, despite its name, Logstash itself does not preserve any data.) Kibana provides a user-friendly interface for querying and visualizing the data.
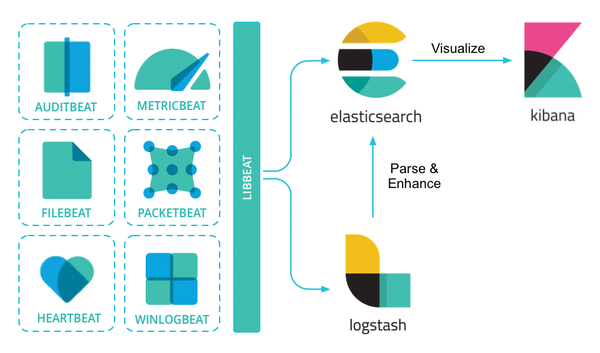 Figure 1: The ELK family and its relatives.
Figure 1: The ELK family and its relatives.
A bundle of tiny apps called beats specialize in collecting data and feeding it to Logstash or Elasticsearch. The beats include:
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Fedora Continues 32-Bit Support
In a move that should come as a relief to some portions of the Linux community, Fedora will continue supporting 32-bit architecture.
-
Linux Kernel 6.17 Drops bcachefs
After a clash over some late fixes and disagreements between bcachefs's lead developer and Linus Torvalds, bachefs is out.
-
ONLYOFFICE v9 Embraces AI
Like nearly all office suites on the market (except LibreOffice), ONLYOFFICE has decided to go the AI route.
-
Two Local Privilege Escalation Flaws Discovered in Linux
Qualys researchers have discovered two local privilege escalation vulnerabilities that allow hackers to gain root privileges on major Linux distributions.
-
New TUXEDO InfinityBook Pro Powered by AMD Ryzen AI 300
The TUXEDO InfinityBook Pro 14 Gen10 offers serious power that is ready for your business, development, or entertainment needs.
-
Danish Ministry of Digital Affairs Transitions to Linux
Another major organization has decided to kick Microsoft Windows and Office to the curb in favor of Linux.
-
Linux Mint 20 Reaches EOL
With Linux Mint 20 at its end of life, the time has arrived to upgrade to Linux Mint 22.
-
TuxCare Announces Support for AlmaLinux 9.2
Thanks to TuxCare, AlmaLinux 9.2 (and soon version 9.6) now enjoys years of ongoing patching and compliance.
-
Go-Based Botnet Attacking IoT Devices
Using an SSH credential brute-force attack, the Go-based PumaBot is exploiting IoT devices everywhere.
-
Plasma 6.5 Promises Better Memory Optimization
With the stable Plasma 6.4 on the horizon, KDE has a few new tricks up its sleeve for Plasma 6.5.