
An XML, HTML, and JSON data extraction tool
Other Options and Variables
In addition to the options that pass or configure the actual commands, --silent suppresses notifications, --verbose shows all notifications, and --debug-arguments shows how command-line arguments were parsed and your queries were evaluated. For support, add --help to get a list of all the available command-line options and --usage to read all the same documentation provided in the README file.
Last but not least, I want to mention global variables. Depending on your request, Xidel will provide the full input text available raw inside $raw or already parsed in JSON format inside $json. If you tell Xidel to download a web page, its full address will be inside $url, and its headers, host, and path will be inside $headers, $host, and $path respectively.
Practical Examples
Now I'll put Xidel to work and show you some practical examples. The simplest possible thing you can ask Xidel is for the title of a web page (auxiliary notifications have been omitted for readability in all examples):
#> xidel https://www.linux-magazine.com --extract //title Linux Magazine
which yields the expected result. Notice that to indicate an element, in this case the title, you must prefix it with a double slash //. You can also give Xidel multiple commands in the same call:
#> xidel https://www.linux-magazine.com -e "//title" https://edition.cnn.com --extract //title Linux Magazine Breaking News, Latest News and Videos | CNN
In this example, I deliberately used both versions of the extract command.
Listing 2 shows the partial output of a simple follow command.
Listing 2
follow Output
#> xidel https://www.linux-magazine.com --follow //a --extract //title > all-titles ... Sparkhaus Shop - Linux Magazines & Online-Services Administration ª Linux Magazine Desktop ª Linux Magazine Web%20Development ª Linux Magazine ... ...
If you compare the four output lines in Listing 2 with the links highlighted in Figure 1, you can see that the command instructed Xidel to download all the pages linked from www.linux-magazine.com and then extract and print those pages' titles.
 Figure 1: The titles output in Listing 2 are from the linked pages highlighted here on the Linux Magazine website.
Figure 1: The titles output in Listing 2 are from the linked pages highlighted here on the Linux Magazine website.
Because XQuery is Turing complete, Xidel can use XQuery to create documents from scratch, without looking anywhere for data, as shown in the following command (also shown on the left side of Figure 2):
#> xidel --xquery '<table>{for $i in 0 to 1000 return <tr><td>{$i}</td><td>{if ($i mod 2 = 0) then "Linux Magazine" else "is great"}</td></tr>}</table>' --output-format xml > test.html
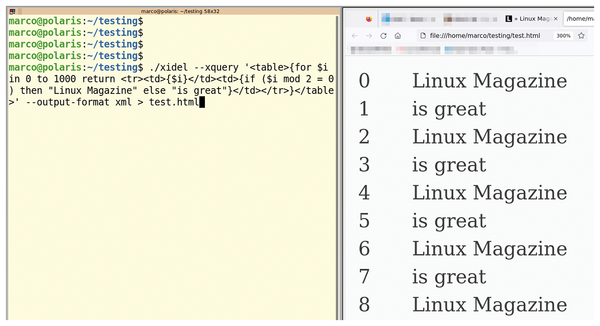 Figure 2: With Xidel, generating HTML tables or other documents is quick and simple.
Figure 2: With Xidel, generating HTML tables or other documents is quick and simple.
This command outputs the test.html web page, which is the HTML table displayed by Firefox on the right side of Figure 2.
Figure 3 and Listing 3 show the --output-format option, which allows Xidel to influence every other Linux system component. Line 1 of Listing 3, whose output, as well as links to its sources, is shown in Figure 3, sets the Bash variable $title to the page's title and makes $links into an array of all the links on the same page. The --output-format bash command tells Xidel to load whatever it finds into Bash variables instead of writing the output to a file, with the specifics declared in the two -e options.
Listing 3
Setting Bash Environment Variables
01 #> eval "$(/home/marco/testing/xidel https://www.linux-magazine.com -e 'title:=//title' -e 'links:=//a/@href' --output-format bash)"
02
03 #> echo $title
04 Linux Magazine
05
06 #> printf '%s\n' "${links[@]}". | grep '^/Online/'
07
08 /Online/News
09 /Online/Features
10 /Online/Blogs
11 /Online/White-Papers
12 /Online/News/Zorin-OS-16.3-is-Now-Available
13 /Online/News/SUSECON-2023
14 /Online/News/Mageia-9-RC1-Now-Available-for-Download
15 /Online/News/Linux-Mint-21.2-Now-Available-for-Installation
16 ...
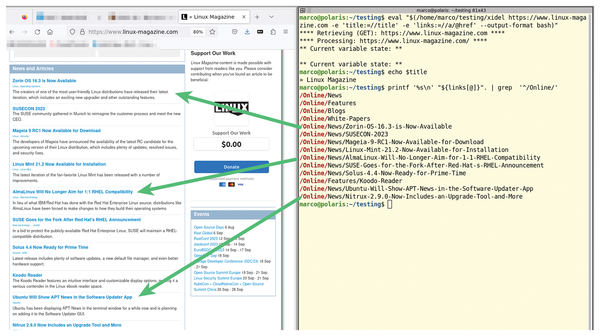 Figure 3: After extracting data from a web page, Xidel can send the data everywhere, including a Linux terminal environment.
Figure 3: After extracting data from a web page, Xidel can send the data everywhere, including a Linux terminal environment.
The first -e option (note its := syntax) copies the title of the given web page (//title) into a shell variable, which is called title for clarity, but as far as the shell is concerned, it could have any other name. The second -e option does the same thing, using //a/@href to signify that all the href values (i.e., the actual URLs) of all the HTML anchor tags (a) that define HTML hyperlinks should be copied inside links. Because there are many such tags, links will automatically become an array instead of a single cell. This is why, in the printf statement in line 6, links is referenced with curly and square brackets.
Cool, huh? But enough of HTML and XML, I'll turn to some JSON examples. In a previous article in Linux Magazine [6], I wrote about the Shaarli bookmark manager (Figure 4), which saves its bookmarks as one JSON array with the structure shown in Listing 4 (heavily edited for clarity).
Listing 4
Shaarli Bookmarks in JSON Format
#> jq '.' shaarli.json | more
[
... other records...
{
"id": 180,
"url": "URL of this bookmark",
"title": "Why AI Will Save The World",
other name/value pairs...
...
},
{
"id": 178,
"url": "URL of this other bookmark",
"title": "Let Them Eat Solar Panels",
other names/values of this other bookmark...
...
}
... many other records...
]
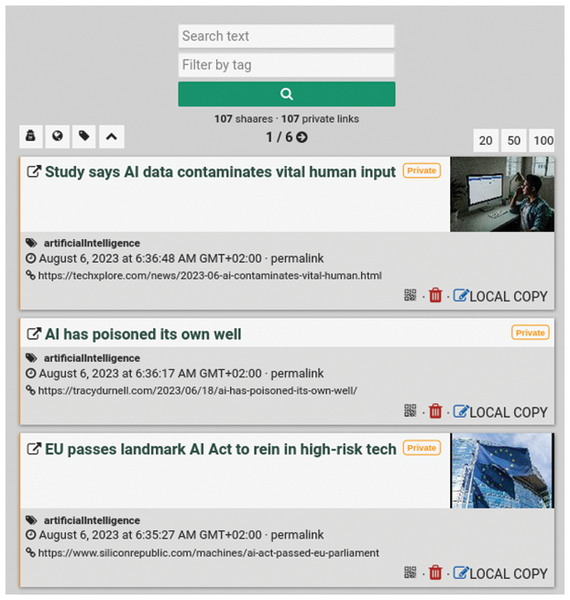 Figure 4: The Shaarli bookmark manager shows some of the bookmarks retrieved by Xidel.
Figure 4: The Shaarli bookmark manager shows some of the bookmarks retrieved by Xidel.
Xidel will read the shaarli.json file that stores the JSON array and fetch each name/value pair of every record, as long as I know its position in the array (see Listing 5).
Listing 5
Extracting a Specific Value
#> xidel shaarli.json -e '$json(4).title' -e '$json(8).title' Why AI Will Save The World Open source licenses need to evolve to deal with AI
Because XQuery is Turing complete and Xidel automatically loads every JSON file you give it into an array called $json, I can use the one-liner loop in Listing 6 to scan the entire array and then filter, with the egrep shell command, all my bookmark titles about artificial intelligence (AI).
Listing 6
Extracting the Bookmark Titles
#> xidel shaarli.json -e 'for $t in $json/title return string-join(("TITLE", $t), " ==> ")' | egrep 'AI|ntelligence'
TITLE ==> Why AI Will Save The World
TITLE ==> AI Is Coming For Your Children
TITLE ==> AI has poisoned its own well
TITLE ==> This AI Boom Will Bust
...
The for command grabs all the title values inside $json and then loads each of them, one at a time, into the auxiliary variable $t. Then, the XQuery string-join function attaches the current title to the constant string TITLE, using as the connector the other string passed as the last argument.
If you want to extract more than one value per bookmark (e.g., both its ID number and title), you can use the concat, which unsurprisingly concatenates all the arguments it gets:
#> xidel -s shaarli.json -e '$json()/concat("ARTICLE|",id,"|",title)'Alternatively, you can use the extended string syntax (note the backticks!) as follows:
#>xidel -s shaarli.json -e '$json()/`ARTICLE|{id}|{title}`'Both commands will produce the same output, part of which is visible in Listing 7. What is really important in both cases is the $json() notation, where the empty parentheses indicate the entire array, not just one of its elements. That's what makes Xidel extract and format, as shown in the second part of the command, the ID and title values of every bookmark.
Listing 7
A Pipe-Separated, Plain Text Excerpt
ARTICLE|102|EU passes landmark AI Act to rein in high-risk tech ARTICLE|134|AI has poisoned its own well ARTICLE|135|Study says AI data contaminates vital human input ARTICLE|176|Open source licenses need to evolve to deal with AI ARTICLE|178|AI Is Coming For Your Children ARTICLE|180|Why AI Will Save The World
Finally, if I want the id column in Listing 7 to always be four characters wide (this works because I have fewer than 10,000 bookmarks), I can tell Xidel to always pad the id value with enough white spaces – even for ID values smaller than 1,000 – by replacing it with the expression
substring(" ",1,4 - string-length(id))||idwhich replaces the leftmost part of a string made of four spaces with the current value of id.
As far as I am concerned, the capability illustrated in these last JSON examples shows Xidel's real power, and my main reason for using it. Formats like the one shown in Listing 7 may be too limited for sophisticated uses, but it would be very hard to find a better compromise between immediate readability, ease of conversion to any other format, and (perhaps most important to me) long-term guaranteed usability, regardless of the software available.
Patterns
Xidel's support for patterns can be very useful if you need to periodically extract dynamic data from web pages with a complex but constant structure, such as an ever-changing Top 10 list on a web forum. Although a thorough presentation on Xidel patterns is outside the scope of this article, I want to briefly describe Xidel, because it may encourage others to try this program.
Listing 8 shows a snippet taken from the Xidel documentation of a pattern file that Xidel can use to fetch titles and links of the "recommended videos" listed on a YouTube page.
Listing 8
Fetching with Patterns
< li class="video-list-item"> <!-- skipped --> Idras Sunhawk Lyrics < li class="video-list-item"> <a> {$title:=.}
The {$title:=.} marker in the last line of Listing 8 shows the XPath syntax to tell Xidel that every time it finds that particular sequence of CSS elements – a list item (li) with CSS class video-list-item, followed by an anchor tag (<a>), followed by a span element whose class is title – then the value of that last element is data that should be saved in a variable called $title.
Visually, Xidel pattern files look similar to Bash here documents or Perl templates, because in all cases, you have a fixed grid, or "mask" of text, in which the elements of interest occupy a fixed place. The difference is that Bash and Perl use those tools to show where already existing variables should be placed, or written, whereas Xidel patterns do just the opposite. At their core, Xidel patterns are regular expressions, too long to fit in one line, that show where to read the values that should be saved, as well as which variables should store them.
Xidel patterns, however, are more powerful than regular expressions, with many options to control how they process what they find. For instance, a Greasemonkey script [7] can create Xidel patterns by just selecting the text to scrape on the corresponding web page.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Endless OS 6 has Arrived
After more than a year since the last update, the latest release of Endless OS is now available for general usage.
-
Fedora Asahi 40 Remix Available for Macs with Apple Silicon
If you've been anticipating KDE's Plasma 6 for your Apple Silicon-powered Mac, then you're in luck.
-
Red Hat Adds New Deployment Option for Enterprise Linux Platforms
Red Hat has re-imagined enterprise Linux for an AI future with Image Mode.
-
OSJH and LPI Release 2024 Open Source Pros Job Survey Results
See what open source professionals look for in a new role.
-
Proton 9.0-1 Released to Improve Gaming with Steam
The latest release of Proton 9 adds several improvements and fixes an issue that has been problematic for Linux users.
-
So Long Neofetch and Thanks for the Info
Today is a day that every Linux user who enjoys bragging about their system(s) will mourn, as Neofetch has come to an end.
-
Ubuntu 24.04 Comes with a “Flaw"
If you're thinking you might want to upgrade from your current Ubuntu release to the latest, there's something you might want to consider before doing so.
-
Canonical Releases Ubuntu 24.04
After a brief pause because of the XZ vulnerability, Ubuntu 24.04 is now available for install.
-
Linux Servers Targeted by Akira Ransomware
A group of bad actors who have already extorted $42 million have their sights set on the Linux platform.
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.